Announcing SquirrelFish

“Hello, Internet!”
WebKit’s core JavaScript engine just got a new interpreter, code-named SquirrelFish.
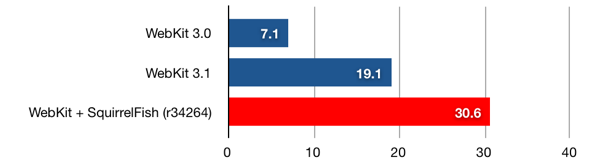
SquirrelFish is fast—much faster than WebKit’s previous interpreter. Check out the numbers. On the SunSpider JavaScript benchmark, SquirrelFish is 1.6 times faster than WebKit’s previous interpreter.
What Is SquirrelFish?
SquirrelFish is a register-based, direct-threaded, high-level bytecode engine, with a sliding register window calling convention. It lazily generates bytecodes from a syntax tree, using a simple one-pass compiler with built-in copy propagation.
SquirrelFish owes a lot of its design to some of the latest research in the field of efficient virtual machines, including research done by Professor M. Anton Ertl, et al, Professor David Gregg, et al, and the developers of the Lua programming language.
Some great introductory reading on these topics includes:
- The Structure and Performance of Efficient Interpreters (Introduces the fundamentals of virtual machine design and explains the importance of direct threading)
- Virtual Machine Showdown: Stack Versus Registers (Details the benefits of register machines, and the importance of copy propagation)
- The Implementation of Lua 5.0 (Outlines the implementation of a real-world register-based bytecode engine, with a sliding register window calling convention)
I’ve also pored over stacks of terrible books and papers on these topics. I’ll spare you those.
Why It’s Fast
Like the interpreters for many scripting languages, WebKit’s previous JavaScript interpreter was a simple syntax tree walker. To execute a program, it would first parse the program into a tree of statements and expressions. For example, the expression “x + y” might parse to
+
/ \
x y
Having created a syntax tree, the interpreter would recursively visit the nodes in the tree, performing their operations and propagating execution state. This execution model incurred a few types of run-time cost.
First, a syntax tree describes a program’s grammatical structure, not the operations needed to execute it. Therefore, during execution, the interpreter would repeatedly visit nodes that did no useful work. For example, for the block “{ x++; }”, the interpreter would first visit the block node “{…}”, which did nothing, and then visit its first child, the increment node “x++”, which incremented x.
Second, even nodes that did useful work were expensive to visit. Each visit required a virtual function call and return, which meant a couple of indirect memory reads to retrieve the function being called, and two indirect branches—one for the call, and one for the return. On modern hardware, “indirect” is a synonym for “slow”, since indirection tends to defeat caching and branch prediction.
Third, to propagate execution state between nodes, the interpreter had to pass around a bunch of data. For example, when processing a subtree involving a local variable, the interpreter would copy the variable’s value between all the nodes in the subtree. So, starting at the “x” part of the expression “f((x) + 1)”, a variable node “x” would return x to a parentheses node “(x)”, which would return x to a plus node “(x) + 1”. Then, the plus node would return (x) + 1 to an argument list node “((x) + 1)”, which would copy that value into an argument list object, which, in turn, it would pass to the function node for f. Sheesh!
In our first rounds of optimization, we squeezed out as much performance as we could without changing this underlying architecture. Doing so allowed us to regression test each optimization we wrote. It also set a very high bar for any replacement technology. Finally, having realized the full potential of the syntax tree architecture, we switched to bytecode.
SquirrelFish’s bytecode engine elegantly eliminates almost all of the overhead of a tree-walking interpreter. First, a bytecode stream exactly describes the operations needed to execute a program. Compiling to bytecode implicitly strips away irrelevant grammatical structure. Second, a bytecode dispatch is a single direct memory read, followed by a single indirect branch. Therefore, executing a bytecode instruction is much faster than visiting a syntax tree node. Third, with the syntax tree gone, the interpreter no longer needs to propagate execution state between syntax tree nodes.
The bytecode’s register representation and calling convention work together to produce other speedups, as well. For example, jumping to the first instruction in a JavaScript function, which used to require two C++ function calls, one of them virtual, now requires just a single bytecode dispatch. At the same time, the bytecode compiler, which knows how to strip away many forms of intermediate copying, can often arrange to pass arguments to a JavaScript function without any copying.
Just the Beginning
In a typical compiler, conversion to bytecode is just a means to an end, not an end in itself. The purpose of the conversion is to “lower” an abstract tree of grammatical constructs to a concrete vector of execution primitives, the latter form being more amenable to well-known optimization techniques.
Therefore, though we’re very happy with SquirrelFish’s current performance, we also believe that it’s just the beginning. Some of the compile-time optimizations we’re looking at, now that we have a bytecode representation, include:
- constant folding
- more aggressive copy propagation
- type inference—both exact and speculative
- specialization based on expression context—especially void and boolean context
- peephole optimization
- escape analysis
This is an interesting problem space. Since many scripts on the web are executed once and then thrown away, we need to invent versions of these optimizations that are simple and efficient. Moreover, since JavaScript is such a dynamic language, we also need to invent versions of these optimizations that are resilient in the context of an unknown environment.
We’re also looking at further optimizing the virtual machine, including:
- constant pool instructions
- superinstructions
- instructions with implicit register operands
- advanced dispatch techniques, like instruction duplication and context threading
- getting computed goto working on Windows
Performance on Windows has extra room to grow because the interpreter on Windows is not direct-threaded yet. In place of computed goto, it uses a switch statement inside a loop.
Getting Involved
If you’re interested in compilers or virtual machines, this is a great project to join. We’re moving quickly, so the best way to come up to speed is to log on to our IRC channel.
As always, testing out nightly builds and reporting bugs is also a great help.
Extra Bonus Updates
We’ve got some extra bonus info: very early draft documentation of the SquirrelFish VM’s opcodes. For those of you who know about VMs, you may find this enlightening, for those who don’t, you may find it is simpler than you expect.
In addition, we have a detailed comparison of Safari 3.1 vs. SquirrelFish, looking at the individual tests, it is interesting to see which sped up the most. If you look at this comparison to Safari 3.0, you can see that we’ve sped up 4.34x overall since Safari 3, and have improved some kinds of code by over an order of magnitude.
SquirrelFish around the web: There’s lots of interesting discussion in the reddit article about this post. And posts from key SquirrelFish developer Cameron Zwarich has performance data and other info, as does occasional WebKit contributor Charles Ying.