Locking in WebKit
Back in August 2015 we replaced all spinlocks and OS-provided mutexes in WebKit with the new WTF::Lock (WTF stands for Web Template Framework). We also replaced all OS-provided condition variables with WTF::Condition. These new primitives have some cool properties:
WTF::LockandWTF::Conditiononly require one byte of storage each.WTF::Lockonly needs two bits in that byte. The small size encourages using huge numbers of very fine-grained locks. OS mutexes often require 64 bytes or more. The small size ofWTF::Lockmeans that there’s rarely an excuse for not having one, or even multiple, fine-grained locks in any object that has things that need to be synchronized.WTF::Lockis super fast in the case that matters most: uncontended lock acquisition. Parallel algorithms tend to avoid contention by having many fine-grained locks. This means that a mature parallel algorithm will have many uncontended lock acquisitions – that is, calls tolock()when the lock is not held, and calls tounlock()when nobody is waiting in line. Similarly,WTF::Conditionoptimizes for the common case of callingnotifywhen no threads are waiting.WTF::Lockis fast under microcontention. A microcontended lock is one that is contended and the critical section is short. This means that shortly after any failing lock attempt, the lock will become available again since no thread will hold the lock for long. This is the most common kind of contention in parallel code, since it’s common to go to great pains to do very little work while holding a lock.WTF::Lockdoesn’t waste CPU cycles when a lock is held for a long time.WTF::Lockis adaptive: it changes its strategy for how to wait for the lock to become available based on how long it has been trying. If the lock doesn’t become available promptly,WTF::Lockwill suspend the calling thread until the lock becomes available.
Compared to OS-provided locks like pthread_mutex, WTF::Lock is 64 times smaller and up to 180 times faster. Compared to OS-provided condition variables like pthread_cond, WTF::Condition is 64 times smaller. Using WTF::Lock instead of pthread_mutex means that WebKit is 10% faster on JetStream, 5% faster on Speedometer, and 5% faster on our page loading test.
Making WTF::Lock and WTF::Condition fit in one byte is not easy and the technique behind this has multiple layers. Lock and Condition offload all thread queueing and suspending functionality to WTF::ParkingLot, which manages thread queues keyed by the addresses of locks. The design of ParkingLot is inspired by futexes. ParkingLot is a portable user-level implementation of the core futex API. ParkingLot also needs fast locks, so we built it its own lock called WTF::WordLock.
This post starts by describing some background on locking. Then we describe the ParkingLot abstraction and how we use this to build WTF::Lock and WTF::Condition. This section also shows some alternate locking algorithms on top of ParkingLot. Then we describe how ParkingLot and WordLock are implemented, hopefully in enough detail to allow for meaningful scrutiny. The post concludes with some performance data, including comparisons to a bunch of lock algorithms.
Background
This section describes some background about locks. This includes the atomic operations that we use to implement locks as well as some classic algorithms like spinlocks and adaptive locks. This section also tries to give appropriate shout-outs to other lock implementations.
Atomic Operations
CPUs and programming languages provide few guarantees about the way that memory accesses interact with each other when executed concurrently, since the expectation is that programmers will prevent concurrent accesses to the same memory by guarding them with locks. But if you’re like me and you like to implement your own locks, you’ll want some lower-level primitives that do have strong guarantees.
C++ provides std::atomic for this purpose. You can use it to wrap a primitive type (like char, int, or a pointer type) with some atomicity guarantees. Provided you stick to the strongest memory ordering (seq_cst), you can be sure that the concurrent executions of std::atomic operations will behave as if they were executed sequentially. This makes it possible to consider whether an algorithm is sound even when run concurrently by envisioning all of the possible ways that its various atomic operations could interleave.
In WebKit, we use our own wrapper called WTF::Atomic. It’s a stripped-down version of what std::atomic provides. We’ll just consider three of its atomic methods: T load(), store(T), and bool compareExchangeWeak(T expected, T desired).
Load and store are self-explanatory. The interesting one is compareExchangeWeak, which implements the atomic CAS (compare-and-swap) operation. This is a CPU primitive that can be thought of as running the following pseudocode atomically:
bool CAS(T* pointer, T expected, T desired)
{
if (*pointer != expected)
return false;
*pointer = desired;
return true;
}
This method is implemented in terms of std::atomic::compare_exchange_weak, which is implemented in terms of the lock; cmpxchg instruction on x86 or in terms of ldrex and strex on ARM. This form of CAS is called weak because we allow it to spuriously do nothing and return false. The opposite is not true – if the CAS returns true, then it must be that during its atomic execution, it saw *pointer being equal to expected and then it changed it to desired.
Spinlocks
Armed with WTF::Atomic, we can implement the simplest kind of lock, called a spinlock. Here’s what it looks like:
class Spinlock {
public:
Spinlock()
{
m_isLocked.store(false);
}
void lock()
{
while (!m_isLocked.compareExchangeWeak(false, true)) { }
}
void unlock()
{
m_isLocked.store(false);
}
private:
Atomic<bool> m_isLocked;
};
This works because the only way that lock() can succeed is if compareExchangeWeak returns true. If it returns true, then it must be that this thread observed m_isLocked being false and then instantly flipped it to true before any other thread could also see that it had been false. Therefore, no other thread could be holding a lock. Either no other thread is calling lock() at all, or their calls to lock() are still in the while loop because compareExchangeWeak is continuing to return false.
Adaptive Locks
Adaptive locks spin only for a little bit and then suspend the current thread until some other thread calls unlock(). This guarantees that if a thread has to wait for a lock for a long time, it will do so quietly. This is a desirable guarantee for conserving CPU time and power.
By contrast, spinlocks can only handle contention by spinning. The simplest spinlocks will make contending threads appear to be very busy and so the OS will make sure to schedule them. This will waste tons of power and starve other threads that may really be able to do useful work. A simple solution would be to make the spinlock sleep – maybe for a millisecond – in between CAS attempts. This turns out to hurt performance on real code because it postpones progress when the lock becomes available during the sleep interval. Also, sleeping doesn’t completely solve the problem of inefficiency when spinning. WebKit has some locks that may be held for a long time. For example, the lock used to control the interleaving between compiler threads and the garbage collector is usually uncontended but may sometimes be held, and contended, for the entire time that it takes to collect the JS heap or the entire time that it takes to compile some function. In the most extreme case, a lock may protect blocking IO. That could happen unexpectedly, for example if a page fault on an innocent-looking load leads to swapping. Some critical sections can take a while and we don’t want contending threads to poll during that time, even if it’s only 1KHz.
There’s no good way to make spinning efficient. If we increase the delay between CAS attempts then we’re just increasing the delay between when the lock gets unlocked and when a contending thread can get it. If we decrease the delay, the lock becomes less efficient. We want a locking algorithm that ensures that if spinning doesn’t quickly give us the lock, our thread will quietly wait until exactly the moment when the lock is released. This is what adaptive locks try to do.
The kinds of adaptive locks that we will implement can be split into two separate data structures:
- Some small, atomic field in memory that summarizes the lock’s state. It can answer questions like, “does anyone hold the lock?” and “is anyone waiting to get the lock?” We will call this the atomic state.
- A queue of threads that are waiting to get the lock, and a mechanism for suspending and resuming those threads. The queue must have its own synchronization primitives and some way to be kept in sync with the atomic state. We say parking to mean enqueuing a thread and suspending it. We say unparking to mean dequeuing a thread and resuming it.
WTF::Lock is WebKit’s implementation of an adaptive lock, optimized for the things that we care about most: low space usage and a great fast path for uncontended lock acquisition. The lock object contains only the atomic state, while the queue is created on-demand inside the ParkingLot. This allows our locks to only require two bits. Like other adaptive locks, WTF::Lock provides a guarantee that if a thread has to wait a long time for a lock, it will do so quietly.
Related Work
If you know that you need an adaptive lock, you can be sure that the mutex implementation on modern OSes will safely adapt to contention and avoid spinning. Unfortunately, most of those OS mutexes will be slower and bigger than a spinlock because of artificial constraints that arise out of compatibility (a pthread_mutex_t is 64 bytes because of binary compatibility with programs that were compiled against ancient implementations that had to be 64 bytes) or the need to support features that you may not need (like recursive locking – even if you don’t use it, pthread_mutex_lock() may have to at least do a check to see if you asked for it).
WebKit’s locking infrastructure is most inspired by Linux’s excellent futex primitive. Futexes empower developers to write their own adaptive locks in just a few lines of code (Franke, Russell, and Kirkwood ’02). Like with futexes, we materialize most of the data for a lock only when that lock experiences contention, and we locate that data by hashing the address of the lock. Unlike futexes, our implementation does not rely on kernel support and so it will work on any OS. The ParkingLot API has some functionality that futexes lack, like invoking callbacks while holding internal ParkingLot locks.
The idea of using very few bits per adaptive lock is widespread, especially in Java virtual machines. For example, HotSpot usually only needs two or three bits for the state of an object’s lock. I’ve co-authored a paper on locking in another Java VM, which also compressed an adaptive lock into a handful of bits. We can trace some of the ideas about how to build locks that are small and fast to meta-locks (Agesen et al ’99) and tasuki locks (Onodera and Kawachiya ’99).
New proposals like std::synchronic and hardware transactional memory also seek to speed up locking. We will show that these techniques don’t exhibit the performance qualities that we want for WebKit.
Despite the basic techniques being well understood in certain communities, it’s hard to find a lock implementation for C++ that has the qualities we want. Spinlocks are widely available, and those are often optimized for using little memory and having great fast paths for uncontended lock acquisition and microcontention. But spinlocks will waste CPU time when the lock isn’t immediately available. OS mutexes know how to suspend threads if the lock is not available, so they are more efficient under contention – but they usually have a slower uncontended fast path, they don’t necessarily have the behavior we want under microcontention, and they require more memory. C++ provides access to OS mutexes with std::mutex. Prior to WTF::Lock, WebKit had a mix of spinlocks and OS mutexes, and we would try to pick which one to use based on guesses about whether they would benefit more from uncontended speed or efficiency under contention. If we needed both of those qualities, we would have no choice but to punt on one of them. For example, we had a spinlock in CodeBlock that should have been adaptive because it protected long critical sections, and we had an OS mutex in our parallel GC that accounted for 3% of our time in the Octane Splay benchmark because of shortcomings in fast path performance. These issues are resolved thanks to WTF::Lock. Also, there was no way to have a small lock (1 byte or less) that was also efficient under contention, since OS mutexes tend to be large. In the most extreme case we will have one lock per JavaScript object, so we care about the sizes of our locks.
Building Locks With ParkingLot
WTF::ParkingLot is a framework for building adaptive locks and other synchronization primitives. Both WTF::Lock and WTF::Condition use it for parking threads until the lock becomes available or the condition is notified. ParkingLot also gives us everything we’ll need to implement the synchronization schemes that are coming to Web standards like SharedArrayBuffer.
Adaptive locks need to be able to park and unpark threads. We believe that synchronization primitives shouldn’t have to maintain their own parking queues, but instead, a single global data structure should provide a way to access queues by using the address of the lock’s atomic state as a key. The concurrent hashtable of queues is called WTF::ParkingLot. Since each thread can be queued only once at any given time, ParkingLot‘s memory usage is bounded by the number of threads. This means that locks don’t have to pay the price for space for a queue. This makes a lot of sense since for WebKit, which usually runs a small number of threads (about ten on my system) but can easily allocate millions of locks (in the worst case, one per JavaScript object).
ParkingLot takes care of queueing and thread suspension so that lock algorithms can focus on other things, like how long to spin for, what kind of delays to introduce into spinning, and which threads to favor when unlocking.
ParkingLot API
Parking refers to suspending the thread while simultaneously enqueuing it on a queue keyed by some address. Unparking refers to dequeuing a thread from a queue keyed by some address and resuming it. This kind of API must have a mechanism for resolving the suspend-resume race, where if a resume operation happens moments before the suspend, then the thread will suspend anyway. ParkingLot resolves this by exposing the fact that the queues are protected by locks. Parking invokes a client callback while the queue lock is held, and gives the client a chance to decide whether they want to proceed or not. Unparking invokes a client callback while the queue lock is held, and tells the client if a thread was dequeued and if there are any more threads left on the queue. The client can rely on this additional synchronization to ensure that racy deadlocks don’t happen.
The basic API of ParkingLot comprises parkConditionally, unparkOne, and unparkAll.
bool parkConditionally(address, validation, beforeSleep, timeout). This takes the const void* address and uses it as a key to find, and lock, that address’s queue. Calls the bool validation() callback (usually a C++ lambda) while the lock is held. If the validation returns false, the queue is unlocked and parkConditionally() returns false.
If the validation returns true, the current thread is placed on the queue and the queue lock is released. Once the queue lock is released, this calls the void beforeSleep() callback. This turns out to be useful for some synchronization primitives, but most locks will pass an empty thunk. At this point, the thread is suspended until some call to unparkOne() dequeues this thread and resumes it. The client can supply a timeout using a ParkingLot::Clock::time_point (ParkingLot::Clock is a typedef for std::chrono::steady_clock). The thread will not stay suspended past that time point.
void unparkOne(address, callback). This takes a const void* address and uses it as a key to find, and lock, that address’s queue. Then unparkOne tries to dequeue one thread. Once it does this, it calls the void callback(UnparkResult), passing a struct that reports if a thread was dequeued and whether the queue is now empty. Then it unlocks the queue lock. If it had dequeued a thread, it signals it now.
void unparkAll(address). Unparks all threads on the queue associated with the given address.
This API gives us everything we need to implement the locking primitives we need: WTF::Lock and WTF::Condition. It also allows us to build userland versions of FUTEX_WAIT/FUTEX_WAKE operations, which are required by SharedArrayBuffer atomics.
WTF::Lock
We have many locks, including locks inside very frequently allocated objects like JavaScriptCore’s Structure. We want a lock object that takes as little memory as possible, so we go to great lengths to make the lock fit in one byte. We do many such tricks in Structure since there is so much pressure to make that object small. We also want the core algorithm to leave open the possibility of having the lock embedded in bitfields, though Lock doesn’t support this because C++ requires objects to be at least one byte. As this section will show, ParkingLot makes it so easy to implement fast locking algorithms that if clients did need to embed a lock into a bitfield, it would be reasonable for them to have their own implementation of this algorithm.
Our goals are to have a lock that:
- Uses as few bits as possible.
- Requires only a CAS on the fast path for locking and unlocking to maximize uncontended throughput.
- Is adaptive.
- Maximizes throughput under contention.
Making the fast path require only a CAS means that WTF::Lock‘s atomic state must be able tell us if there are any threads parked. Otherwise, the unlock() function would have to always call ParkingLot::unparkOne() in case there were threads parked. While such an implementation would be functional, it would be far from optimal. Afterall, ParkingLot::unparkOne() is obligated to do hashing, acquire some queue lock, and call a callback. This is a lot more work than we want in the common path of unlock().
This implies having two bits for the atomic state:
isLockedBitto indicate if the lock is locked.hasParkedBitto indicate if there may be threads parked.
Locking is allowed to proceed any time the isLockedBit is clear even if the hasParkedBit is set. This property is called barging. We will dive into the implications of barging later.
If locking does not succeed, the algorithm chooses between trying again and parking the thread. Prior to parking, it sets the hasParkedBit. The validation callback it passes to parkConditionally checks that the lock still has both isLockedBit and hasParkedBit set. We don’t want to park if isLockedBit is clear since this means that the lock is available. We don’t want to park if hasParkedBit is clear since this means that the lock has forgotten that we are about to park.
If the hasParkedBit is clear, then unlocking just clears the isLockedBit. If the hasParkedBit is set, it calls unparkOne() passing a callback that really unlocks the lock. This callback will set the lock’s state to either hasParkedBit or 0, depending on whether the UnparkResult reports that there are still more threads on the queue.
We call this basic algorithm a barging lock, and a basic implementation might look like this:
class BargingLock {
public:
BargingLock()
{
m_state.store(0);
}
void lock()
{
for (;;) {
uint8_t currentState = m_state.load();
// Fast path, which enables barging since we are happy to grab the
// lock even if there are threads parked.
if (!(currentState & isLockedBit)
&& m_state.compareExchangeWeak(currentState,
currentState | isLockedBit))
return;
// Before we park we should make sure that the hasParkedBit is
// set. Note that because compareAndPark will anyway check if the
// state is still isLockedBit | hasParkedBit, we don't have to
// worry too much about this CAS possibly failing spuriously.
m_state.compareExchangeWeak(isLockedBit,
isLockedBit | hasParkedBit);
// Try to park so long as the lock's state is that both
// isLockedBit and hasParkedBit are set.
ParkingLot::parkConditionally(
&m_state,
[this] () -> bool {
return m_state.load() == isLockedBit | hasParkedBit;
});
}
}
void unlock()
{
// We can unlock the fast way if the hasParkedBit was not set.
if (m_state.compareExchangeWeak(isLockedBit, 0))
return;
// Fast unlocking failed, so unpark a thread.
ParkingLot::unparkOne(
&m_state,
[this] (ParkingLot::UnparkResult result) {
// This runs with the queue lock held. If mayHaveMoreThreads
// is true, we unlock while leaving the hasParkedBit set.
if (result.mayHaveMoreThreads)
m_state.store(hasParkedBit);
else
m_state.store(0);
});
}
private:
static const uint8_t isLockedBit = 1;
static const uint8_t hasParkedBit = 2;
Atomic<uint8_t> m_state;
};
WTF::Lock closely follows this algorithm, but has additional performance tweaks like spinning and inline fast paths.
Spinning
Adaptive locks combine parking and spinning. Spinning is great because it protects microcontention scenarios from doing parking. Microcontention is when a thread fails the fast path lock acquisition because the lock is not available right now, but that lock will become available in less time than what it would take to park and then unpark. Before WTF::Lock::lock() parks a thread, it will spin 40 times, calling yield between spins. This turns out to be good enough across a while range of platforms. The algorithm can be visualized as follows:
// Fast path:
if (m_word.compareExchangeWeak(0, isLockedBit))
return;
// Spin 40 times:
for (unsigned i = 40; i--;) {
// Do not spin if there is a queue.
if (m_word.load() & hasParkedBit)
break;
// Try to get the lock.
if (m_word.compareExchangeWeak(0, isLockedBit))
return;
// Hint that now would be a good time to context switch.
sched_yield();
}
// Now do all of the queuing and parking.
// ...
This is a known-good approach, which we borrow from JikesRVM’s locks. We suspect that this algorithm, including the spin limit set at 40, is portable enough for our needs. JikesRVM experiments found it to be optimal on a 12-way POWER machine in 1999. I found that it was still optimal when I tried to optimize those locks further on Intel hardware with various CPU and memory topologies. Microbenchmarks that I ran for this post confirm that 40 is still optimal, and that there is a broad plateau of near-optimal settings between about 10 and 60 spins.
Fast Paths
WTF::Lock is structured around an inline fast path for lock() that just does a single lock attempt, and an inline fast path for unlock() that unlocks the lock if there is nobody parked. Having small inline fast paths means that most lock clients will only pay the price of a CAS on locking and unlocking.
Summary of WTF::Lock
WTF::Lock is a high performance lock that fits in one byte. The underlying algorithm only needs two bits, so it would be suitable for cramming a lock into a bitfield. See wtf/Lock.h and wtf/Lock.cpp for the full implementation.
Barging and Fairness
WTF::Lock makes a particular choice about how to handle unlocking: it clears the isLockedBit, which makes the lock available to any thread, not just the one it unparks. This implies that the thread that has been waiting for the longest may have the lock stolen from it by some other thread, which may not have waited at all. A thread that suffers such defeat has no choice but to park again, which puts it at the end of the queue.
This shortcoming can be fixed by having unlock() unpark a thread without releasing the lock. This kind of protocol hands off ownership of the lock from the thread doing the unlocking to the thread that had waited the longest. If the lock also lacks an adaptive spin loop, then this protocol enforces perfect FIFO (first-in, first-out) discipline on threads contending for a lock. FIFO is an attractive property, and it ensures that no thread will get the lock stolen from it.
However, allowing barging instead of enforcing FIFO allows for much higher throughput when a lock is heavily contended. Heavy contention in systems like WebKit that use very fine-grained locks implies that multiple threads are repeatedly locking and unlocking the same lock. In the worst case, a thread will make very little progress between two critical sections protected by the same lock. In a barging lock, if a thread unlocks a lock that had threads parked then it is still eligible to immediately reacquire it if it gets to the next critical section before the unparked thread gets scheduled. Barging permits threads engaged in microcontention to take turns acquiring the lock many times per turn. On the other hand, FIFO locks force contenders to form a convoy where they only get to hold the lock once per turn. This makes the program run much slower than with a barging lock because of the huge number of context switches – one per lock acquisition!
Futex Algorithms and ParkingLot
ParkingLot is very similar to futexes. Both primitives follow the principle that a lock should not have to maintain its own queue. Futexes get help from the kernel and have a richer API, which enables some locking protocols that would be impossible to implement with ParkingLot, like priority inheritance locks. However, ParkingLot is powerful enough to support the basic FUTEX_WAIT/FUTEX_WAKE operations that form the core of futexes.
FUTEX_WAIT can be implemented as follows:
enum Result {
TimedOut, // Timeout was reached.
TryAgain, // The comparison failed.
Success // The thread parked and then unparked.
};
Result wait(Atomic<int32_t>* futex, int32_t expected,
Clock::time_point timeout)
{
bool comparisonSucceeded = false;
bool result = ParkingLot::parkConditionally(
futex,
[&] () -> bool {
comparisonSucceeded = futex->load() == expected;
return comparisonSucceeded;
},
[] () { },
timeout);
if (result)
return Success;
if (comparisonSucceeded)
return TimedOut;
return TryAgain;
}
ParkingLot abstracts a simple version of this behind an API called parkConditionally().
FUTEX_WAKE that wakes one thread (the common case) can be implemented as a call to unparkOne:
bool wake(Atomic<int32_t>* futex)
{
return ParkingLot::unparkOne(futex).didUnparkThread;
}
Being able to emulate core futex functionality means that we can implement various kind of futex-based lock algorithms. We have done this for the purpose of benchmarking our lock implementations. Here are some of the lock algorithms that we have implemented:
ThunderLock: simple lock algorithm that unparks all threads anytime there had been threads parked. This releases a thundering herd of threads that all try to grab the lock. All but one will have to park again. This algorithm is simpler thanBargingLockand requires only three states. It’s easy to implement this with futexes, which support a variant ofWAKEthat wakes all threads. This is also a great algorithm to use if multiple locks share the same address.CascadeLock: adaptive lock that is similar to glibc‘slowlevellockalgorithm used forpthread_mutexon Linux. This algorithm unparks at most one thread onunlock(). The hard part of an adaptive lock that unparks at most one thread is determining when the atomic state is allowed to forget that there are threads parked. The sooner the atomic state claims there are no thread parked, the soonerunlock()calls can take the fast path. But we don’t want to forget parked threads too soon, as this could lead to deadlock.WTF::Locksolved this problem by using theunparkOne()callback, but that’s not available to futexes. Instead,CascadeLocksolves this problem by having any thread that parks acquire the lock in theLockedAndParkedstate. This conservatively ensures that we never forget about parked threads. It also means that as soon as a thread succeeds in acquiring the lock without parking and no other threads are contending, the lock will forget the parked state and future unlocks will be fast.HandoffLock: This is a strict first-in, first-out lock that hasunlock()hand off lock ownership to the thread it unparks. This lock is more deterministic than the other algorithms, but as we will show in our performance evaluation, it’s also a lot slower.
Additionally, we’ve also implemented a version of WTF::Lock in this same style so that it’s easy to compare to the other algorithms:
BargingLock: configurable version ofWTF::Lock. This lock cannot be implemented using futexes because it requires a callback inunparkOne(), which onlyParkingLotprovides.
WTF::Condition
The park/unpark operations of ParkingLot align perfectly with the needs of condition variables. WTF::Condition supports lots of condition-variable primitives, like various kinds of waiting with a timeout. In this section we just consider the three most basic primitives, since the other ones are easy to build on top of these: wait, notifyOne, and notifyAll.
The hardest part of a condition variable is that it must appear to unlock the lock at the same time that the thread waits on the condition. Unlocking the lock and separately waiting on the condition would mean that notify operations could happen just after unlocking and just before waiting. We address this with the beforeSleep callback to parkConditionally. This callback runs just after the ParkingLot places the calling thread on a parking queue, but just before the thread is actually parked. This means that as soon as the lock is unlocked, any notify operations are guaranteed to release this thread from the condition variable.
This is a simple and precise algorithm, which ensures that wait will never return unless the condition was notified.
Interestingly, this algorithm means that WTF::Condition doesn’t actually need to place any data into its atomic state – it just uses it to access a queue in the ParkingLot, which then does all of the work. We exploit this to use the contents of the Condition to just record whether there are any waiters. We use the various other callbacks from ParkingLot to maintain this cache, and we use it to make notifyOne/notifyAll very fast when there isn’t anyone waiting: they just return without calling into ParkingLot.
The complete algorithm for the fundamental Condition operations is:
class Condition {
public:
Condition()
{
m_hasWaiters.store(false);
}
void wait(Lock& lock)
{
ParkingLot::parkConditionally(
&m_hasWaiters,
[this] () -> bool {
// This is the validation callback. It runs with the queue lock
// held. We will return true, so we know that the queue will
// have waiters before we release the queue lock.
m_hasWaiters.store(true);
return true;
},
[this, &lock] () {
// This is the beforeSleep callback. It runs once our thread
// is on the parking queue and so will definitely be notified -
// and so won't actually sleep - if an unpark operation
// happens. This runs after we have already unlocked the queue
// lock, so it's safe to do whatever we like. We use this as an
// opportunity to unlock the lock.
lock.unlock();
});
lock.lock();
}
void notifyOne()
{
if (!m_hasWaiters.load())
return;
ParkingLot::unparkOne(
&m_hasWaiters,
[this] (ParkingLot::UnparkResult result) {
m_hasWaiters.store(result.mayHaveMoreThreads);
});
}
void notifyAll()
{
if (!m_hasWaiters.load())
return;
m_hasWaiters.store(false);
ParkingLot::unparkAll(&m_hasWaiters);
}
private:
Atomic<bool> m_hasWaiters;
};
This case illustrates some differences from futexes. Supporting condition variables with futexes requires a bit more magic, since we have to unlock the lock before calling FUTEX_WAIT. That would allow a notify call to happen in between the unlocking and the waiting.
One way around this is to use the atomic state to indicate if there is currently any thread stuck in between unlocking and waiting. We would set it to true at the start of wait, and set it to false at the start of notify. Unfortunately, that would lead to spurious returns from wait: anytime a notify operation happens just before we get to FUTEX_WAIT, the wait will return even if the notify also woke up some other thread. This would be a valid implementation of wait according to pthreads and Java, since those allow for spurious wakeups.
We like that ParkingLot allows us to avoid spurious wakeups. When debugging concurrent code, it’s great to be able to isolate what happened. Ensuring that wait only returns as a result of a notification is a welcome dose of determinism when trying to understand the behavior of a concurrent program.
WTF::Lock and WTF::Condition both take just one byte and implement all of the features you’d expect from such synchronization primitives. This is possible due to the flexibility of the ParkingLot API. ParkingLot is also powerful enough to support many futex-based algorithms, since ParkingLot::compareAndPark/unparkOne are intra-process equivalents of FUTEX_WAIT/FUTEX_WAKE.
Implementing WTF::ParkingLot
WTF::ParkingLot provides the primitives needed to build any kind of adaptive lock. ParkingLot is a collection of queues of parked threads. Queues are keyed by the address of their lock’s atomic state. ParkingLot is based on a concurrent hashtable to maximize parallelism – even if many threads are experiencing contention and need to do things to the queues, those threads will likely get to do their queue operations in parallel because the hashtable has no single bottleneck.
We use ParkingLot to save memory in locks. A risk with any side-table approach is that we are just shifting space consumption from the lock object to the ParkingLot. Fortunately, ParkingLot gives us a strong guarantee: the size of ParkingLot is bounded by the number of threads. It mostly relies on thread-local objects, which it allocates on-demand and destroys automatically when threads die. As we will show, all of ParkingLot‘s data structures obey the rule that their size is asymptotically bounded by the number of threads. This means that the number of locks and even the rate at which you contend on them has no impact on the hard O(threads) space bound of ParkingLot. In exchange for this fixed per-thread overhead, ParkingLot enables all of your locks to take only one byte each.
There are three fundamental operations: parkConditionally, unparkOne, and unparkAll. We’ll describe just the first two in this section, since unparkAll is trivial to implement using the same logic as unparkOne.
Concurrent Hashtable of Synchronized Queues
An easy way to implement ParkingLot is to have a single lock that guards a hashtable that maps addresses to queues. This would probably work great for programs that weren’t very parallel, but that lock will become a bottleneck in programs with lots of threads. ParkingLot avoids this bottleneck by using a concurrent hashtable.
The intuition behind concurrent hashtables is that different threads are unlikely to interfere with each other because they are likely to do accesses using different keys, which hash to different buckets. Therefore even concurrent writes are likely to proceed in parallel. The most sophisticated concurrent hashtable algorithms use lock-free data structures throughout. But a simpler approach is to just put a lock around each bucket. This is the approach we take in ParkingLot. The algorithm turns out to be fairly simple because we do not have to optimize resizing. We can take these shortcuts because:
- There is only one concurrent hashtable.
ParkingLotis not instantiable. All of its member functions are static. So there is only one of these concurrent hashtables in any process. - Its size is bounded by the number of threads. A thread takes a lot of memory already. This means that we don’t have to be worried about the space consumption of this hashtable, so long as it’s O(threads) and the per-thread overhead is significantly smaller than a typical thread stack.
- We must acquire a lock associated with the queue once we find it in the hashtable. This means that it wouldn’t be too beneficial to make the hashtable itself lock-free. All users of it will grab a lock anyway. This motivates a solution that doesn’t involve a lock-free concurrent hashtable – just one that attempts to minimize lock contention.
- Iterating over the whole table is uncommon and not very important. This means that iteration, like resizing, can be gross.
Our resizing algorithm will leak the old (smaller) hashtable. This is essential for making the algorithm sound. Because there is only one ParkingLot and its size is bounded by the number of threads, we can compute a hard bound on the amount of leaked memory.
The most important part of our resizing algorithm is that it makes resizing an extremely rare event. Resizing the table only happens when the following conditions arise:
- a thread parks itself for the first time.
- the thread count at that time is greater than one third of the hashtable’s size.
This ensures that resizing occurs only when the high watermark of threads increases. When we grow the table, we always make the new size be twice what we need. These rules combined ensure that if the max number of threads that were active at any time is N then the number of resizes we have ever done is at most log(N). Since we know that we can implement a very bad resize algorithm, we’ll first consider how to make the ParkingLot work in the absence of resizing.
Simplified Algorithm for a Fixed-Size Hashtable
Let’s assume that the hashtable size is fixed and all threads agree on a pointer to the hashtable. This allows us to consider a simpler version of the algorithm. We’ll worry about adding resizing later.
The basic algorithm we use is that each hashtable bucket is a queue. Each bucket has a lock (specifically, a WordLock, described later in this section) to protect itself. We use this lock as the queue lock for the purpose of the ParkingLot API. The hashtable only supports enqueue and dequeue, so collisions are handled by simply interleaving the collided queues. For example, if addresses 0x42 and 0x84 both hash to bucket at index 7, and you perform a sequence of enqueue operations like:
- enqueue(0x42, T1)
- enqueue(0x42, T2)
- enqueue(0x84, T3)
- enqueue(0x84, T4)
Then the bucket at index 7 will point to a queue that looks like:
head -> {addr=0x42, thr=T1} -> {addr=0x42, thr=T2} -> {addr=0x84, thr=T3} -> {addr=0x84, thr=T4} <- tail
This design means that enqueuing doesn’t have to worry about collisions at all; it just records the actual desired address in the queue node (i.e. the ThreadData for the current thread). Dequeuing resolves collisions by finding the first element in the list, starting at head, that has the address we are dequeuing for.
After enqueuing a thread when parking, ParkingLot must suspend it until it is dequeued during unparking. ParkingLot uses a thread-local condition variable to suspend threads. Only large overheads matter on this code path, since its performance is dominated by the work that the OS has to do to make the thread not runnable anymore. Hence, it’s fine for ParkingLot to bottom out in OS condition variable code.
In this design, ParkingLot::parkConditionally proceeds as follows:
- Hash the provided atomic state address to get the index into the hashtable. Better yet, this gives us a pointer to our bucket. From here on, we only worry about this bucket.
- Lock the bucket’s lock.
- Call the provided validation callback. The bucket’s lock is also the queue lock for the client’s atomic state address, so calling the validation callback here satisfies the contract of
parkConditionally. If the validation fails, we release the bucket lock and return. - If the validation succeeds, we enqueue the current thread by appending it to the linked list at the tail. The current thread’s
ThreadDatawill contain the address that we are parking on. - Unlock the bucket’s lock.
- Call the
beforeSleepcallback. Doing work at this point turns out to be great for condition variables; more on that later. - Wait on the current thread’s parking condition variable.
Unparking a thread via ParkingLot::unparkOne proceeds as follows:
- Hash the provided atomic state address to get the bucket pointer.
- Lock the bucket’s lock.
- Search forward from head to find the first entry in the queue that matches our address, and then remove that entry. We may not find any such entry. The queue may even be completely empty.
- Call the provided callback, telling it if we dequeued any threads and if the queue has any more elements. Giving this information to the client while we hold the bucket’s lock turns out to be great for locks; more on that later.
- Unlock the bucket’s lock.
- If we had dequeued a thread, tell it that it can wake up now by signaling its parking condition.
The other operations on ParkingLot are simple variations on these two. ParkingLot::compareAndPark is just a wrapper for parkConditionally, and unparkAll is almost like unparkOne except that it finds all of the entries matching the address rather than just the first one.
Resizing the Hashtable
We don’t want to make a guess about how many threads the process will have. WebKit contributors sometimes like to add threads, and we don’t want to discourage that. Web APIs can cause WebKit to start threads, and the number of threads can be controlled by the web page. Therefore, we don’t want to get into the business of guessing how many threads we will see. This implies that the hashtable must be resizable.
If we lock every bucket in the current hashtable, then we have exclusive access to the table and we can do with it as we wish. Any other thread wishing to access the table will be stuck trying to acquire the lock of some bucket, since the park/unpark operations from the previous section all start with locking some bucket’s lock. The intuition is that resizing can simply lock all of the old table’s buckets and then allocate a new hashtable and copy the old one’s contents into it. Then, while still holding the locks of all of the buckets, it can repoint the global hashtable pointer to the new table. Then we can release the locks on the old table’s buckets. This implies another change: the park/unpark algorithms will check if the global hashtable pointer is still the same after the bucket lock is locked. Without resizing, the park implementation might have looked like:
void ParkingLot::parkConditionally(...)
{
Hashtable* hashtable = g_hashtable; // load global hashtable pointer.
Bucket* bucket = hashtable->buckets[hash % hashtable->size];
bucket->lock.lock();
// The rest of the parking algorithm...
}
Resizing means that any hashtable operation begins like this instead:
void ParkingLot::parkConditionally(...)
{
Bucket* bucket;
for (;;) {
Hashtable* hashtable = g_hashtable;
bucket = hashtable->buckets[hash & hashtable->size];
bucket->lock.lock();
if (hashtable == g_hashtable)
break;
// The hashtable resized while we were waiting for the lock. Try
// again.
bucket->lock.unlock();
}
// At this point, we will have a bucket, it will be locked, and the
// hashtable is not resizing.
// The rest of the parking algorithm...
}
After resizing, we need to leak the old hashtable. We cannot be sure after unlocking all of its buckets how many threads are still stuck between having loaded the old hashtable pointer and attempting to lock a bucket. Threads may be stuck in between any two instructions for an indeterminate amount of time due to OS scheduling. Worse, a bucket’s lock may have any number of threads waiting on it, so we cannot delete the lock. Rather than try to ask the OS about the status of all threads in the system to detect when it’s safe to delete the old table, we just leak the old hashtables. This is fine because of exponential resizing. Let’s say that the hashtable started with a size of 1 and resized up to 64. Then we will have allocated hashtables of the following sizes:
1 + 2 + 4 + 8 + 16 + 32 + 64
This is a geometric series, which converges to 127 (i.e. 64 * 2 – 1). In general, the amount of memory we will waste due to leaking old tables is proportional to the amount of memory used by the current table. Somewhat humorously, the ParkingLot will record all “leaked” hashtables in a global vector to ensure that leak detector tools don’t bother us about these harmless and intentional leaks.
We optimize this a bit further, by having the buckets be separate heap-allocated objects. The hashtable just contains pointers to buckets, and we reuse buckets across resizings. This means that the only thing that we leak are the bucket pointer arrays, which are an order of magnitude smaller than the total size of all of the buckets. In our implementation, the leak is bounded (total amount of leaked memory is bounded by the amount of memory we are using) and very small (it’s bounded by the size of the pointer array, which is much smaller than the total amount of memory used for buckets, which in turn is bounded by the number of threads and is much smaller than the total amount of memory that threads use for other things like stacks).
Summary of WTF::ParkingLot
To summarize, ParkingLot provides parking queues keyed by the memory addresses of locks. The memory usage of ParkingLot has nothing to do with the number of locks – it’s bounded by the number of threads currently parked (which is bounded by the number of threads). Using some simple concurrency tricks, ParkingLot is able to provide parallelism when different threads are queueing on different addresses. See wtf/ParkingLot.h and wtf/ParkingLot.cpp for the full implementation.
WTF::WordLock
WTF::ParkingLot needs a lock implementation for protecting buckets. This shouldn’t be a spinlock because we don’t put a bound on the amount of code that may execute while the lock is held. ParkingLot will use this lock to synchronize the validation in parkConditionally() and the callback in unparkOne(). Even though those callbacks usually do very little work, we don’t want to place strict limits on them. We also need the lock to behave well under microcontention and to not take too much memory. This means that we need something like WTF::Lock.
Fortunately, it’s possible to implement that algorithm without a ParkingLot if we’re willing to use an entire pointer-sized word. This is what WTF::WordLock gives us. It’s less desirable than WTF::Lock, since it requires more memory, but it’s standalone so that we can use it for all of the locking needs of ParkingLot. A WordLock instance just has a Atomic<uintptr_t> inside it. There is no other overhead except for some small per-thread data structures that get created the first time that a thread contends for a lock and get destroyed automatically when the thread dies.
A lock needs three data structures: the atomic state, a queue of threads, and a lock to protect the queue. In our BargingLock algorithm, the atomic state comprises a bit that tells us if the lock is locked and a bit that tells us the queue is non-empty. WordLock adapts this algorithm by having the atomic state be a pointer to the head of the queue, with the two low-order bits of the pointer stolen to represent whether the lock is locked and whether the queue is locked. We interpret the atomic state as follows:
- The lowest bit is the
isLockedBit. - The second-lowest bit is the
isQueueLockedBit. - The rest of the bits are a pointer to the head of the queue, or null if it is empty.
The queue is represented using ThreadData objects. There is one such object per thread. It contains the pointers necessary to manage the queue, including a next pointer and a tail pointer. We use the convention that the head of the queue points to the tail, which obviates the need to allocate any other memory for storing a pointer to tail: the atomic state just points to head, which gives an O(1) way of finding the tail.
In all other regards, WTF::WordLock follows the BargingLock algorithm. Our experiments will show that except for space usage, WordLock performs just as well as Lock. See wtf/WordLock.h and wtf/WordLock.cpp for the full implementation.
Performance
We replaced all of the locks in WebKit with WTF::Lock because it was safer than spinlocks (no chance of a thread wasting time in a spin loop) and both faster and smaller than OS-provided mutexes. This section shows the performance implications of this change, including some exploration of locking protocols that WebKit does not use but that we either discovered by accident or that we’ve heard of others using.
This section first shows the performance of WTF::Lock when running WebKit benchmarks, and then shows some microbenchmark results using a bunch of different lock variants.
WebKit Performance With WTF::Lock
Prior to WTF::Lock, WebKit used a mix of OS-provided mutexes and spinlocks. We would guess how important the lock was for fast path performance and space and how long the critical section was going to be. We would always use OS-provided mutexes for critical sections that we thought might be long. We had data that suggested that we had picked incorrectly in at least some cases: some of those OS-provided mutexes were slowing us down and some of the spinlocks would cause sched_yield to show up in time profiles. The difficulty of guessing what kind of lock to use motivated us to implement WTF::Lock.
It’s now difficult to revert this change and return to a world where we pick different locks for different critical sections, and we suspect that using spinlocks is generally not a good idea. If some part of the code unexpectedly takes a long time, for example due to swapping, then the last thing we want is for other threads to start busy-waiting for the lock. We also knew from experience that trying to alleviate that program by making spinlocks sometimes sleep would only degrade performance in the common case.
This section sets out to establish that if you know that you need an adaptive lock then WTF::Lock is what you want to use. We use three benchmarks: JetStream 1.1, Speedometer 1.0, and PLT3 (our internal page load time test). All of these benchmarks are run in a Mac Pro with two 2.7 GHz 6-Core Xeon E5 CPUs (with hyperthreading, so 24 logical CPUs) and 16 GB RAM running El Capitan. The “OS Mutex” results are from replacing WTF::Lock with a wrapper for pthread_mutex_t. The WTF::Lock results are the baseline. These numbers are gathered using WebKit r199680 with r199690 backported (since it affected performance on this machine).
JetStream Performance

This chart shows the JetStream score for both OS Mutex and WTF::Lock. Higher is better.
JetStream is a JavaScript benchmark that consists of small to medium-sized programs that stress various parts of our JavaScript engine. WebKit relies on locks heavily when running JavaScript programs. In the most extreme case, each object may have its own lock and this lock may be acquired on any property access. This is necessary to allow our concurrent compiler to inspect the heap. Without locks, those accesses would not be safe. These JetStream numbers show that it’s important to have fast locks when running JavaScript.
Speedometer Performance

This chart shows the Speedometer score for both OS Mutex and WTF::Lock. Higher is better.
Speedometer is a JavaScript and DOM benchmark comprised of web apps implemented in different web frameworks. It stresses the entire engine. We can see that for this realistic test, WTF::Lock gives a 5% speed-up.
PLT3 Performance

This chart shows PLT3 geometric mean page load times. Lower is better.
PLT3 speeds up by 5% if you switch to WTF::Lock. Since PLT3 is not entirely dominated by JavaScript, this suggests that there are many other locks in WebKit that benefit from being fast.
Summary of WebKit Lock Performance
WTF::Lock is always a speed-up over pthread_mutex_t. It’s also 64x smaller – it uses only one byte while pthread_mutex_t uses 64 bytes. Based on this data, we are confident that the right choice is to continue using WTF::Lock instead of pthread_mutex.
Microbenchmark Performance
This section explores the performance of various locks on a simple microbenchmark that can start any number of threads which repeatedly lock a lock and do some small amount of floating point math (each loop iteration does one double addition and multiplication). We can vary the locking protocol and some parameters of the locking protocol (like the amount of spinning it will do before parking). This compares WTF::Lock and WTF::WordLock to spinlocks and miscellaneous lock algorithms that use ParkingLot. This section also compares WTF::Lock to std::synchronic and hardware transactional memory.
These benchmarks are run on a MacBook Pro with a 2.6 GHz Intel Core i7 with four cores and hyperthreading and 16 GB of RAM running El Capitan.
Microcontention for Various Thread Counts
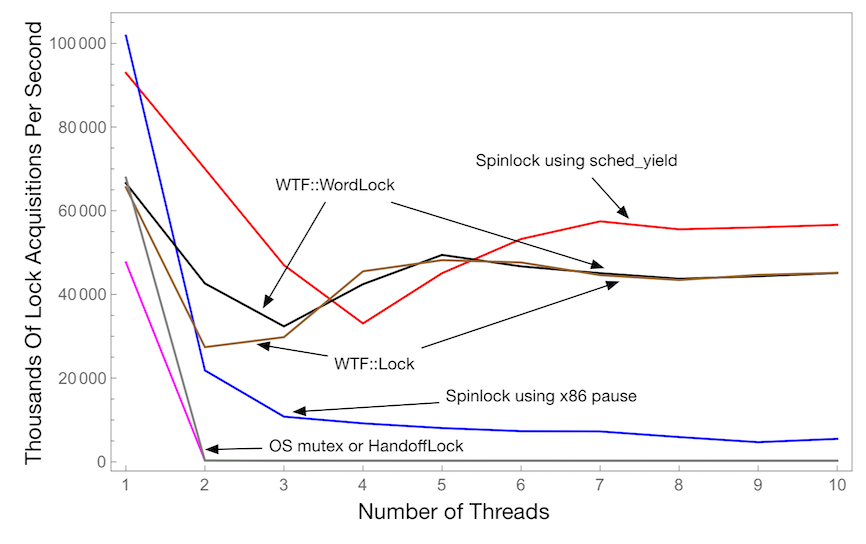
This chart shows the number of successful lock acquisitions per second across all threads as a function of the number of threads. This uses a critical section that does one loop iteration while holding the lock. Higher is better.
We use six locking protocols:
- OS mutex.
HandoffLock. This is a completely fair mutex implemented usingParkingLot.- Spinlock that uses
sched_yieldwhile spinning. - Spinlock that uses the x86
pauseinstruction while spinning. WTF::WordLock.WTF::Lock.
This chart shows that as you scale up the number of threads, WTF::Lock can easily hold its own. It’s hard to tell how slow that OS mutex and HandoffLock are. In fact, for 10 threads they are about 160x slower.
Notice that for a single thread, the fastest locks are always spinlocks. This is because spinlocks do not have to use CAS when unlocking. Using CAS when unlocking is necessary for locks that have a queue, since you need to check for parked threads at the moment that you unlock. Spinlocks don’t do this, so they can just store 0 – or whatever the “I’m not locked” value is – into the lock’s atomic state.
It’s also clear that depending on the number of threads contending, different locks have very different performance. It appears that WTF::Lock is not so great for two or three threads.
Finally, it’s clear that the x86 pause instruction is not useful for our spinlocks. Intel shows that it is a speed-up, but we cannot confirm their claim.
Optimizing the Spin Limit of WTF::Lock
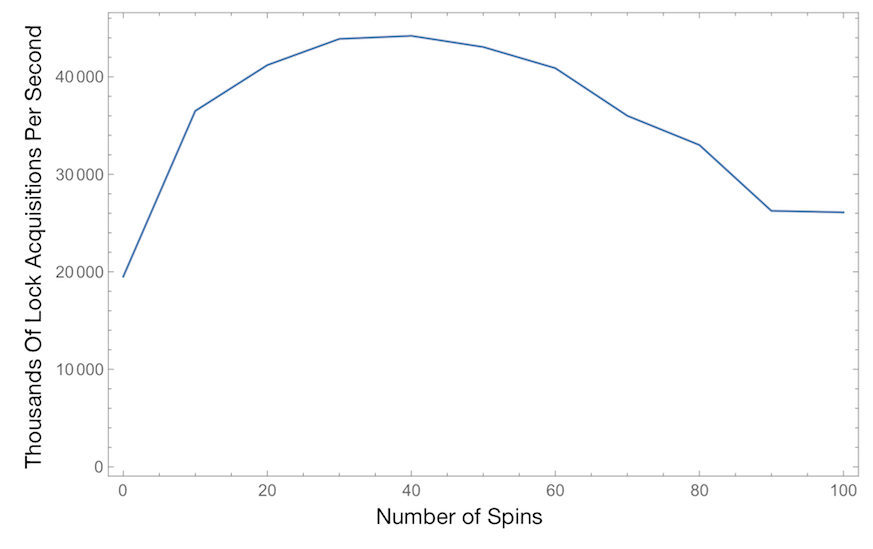
This chart shows the number of successful lock acquisitions per second across all threads as a function of the spin limit. Higher is better. This test uses 4 threads, since for fewer threads the spin limit doesn’t matter much, and for more threads the chart doesn’t look much different than this. This uses a critical section that does one loop iteration while holding the lock.
We initially picked a spin limit of 40 based on ancient JikesRVM experiments. Surprisingly, this chart precisely confirms that 40 is still optimal.
Microcontention With Different Locks
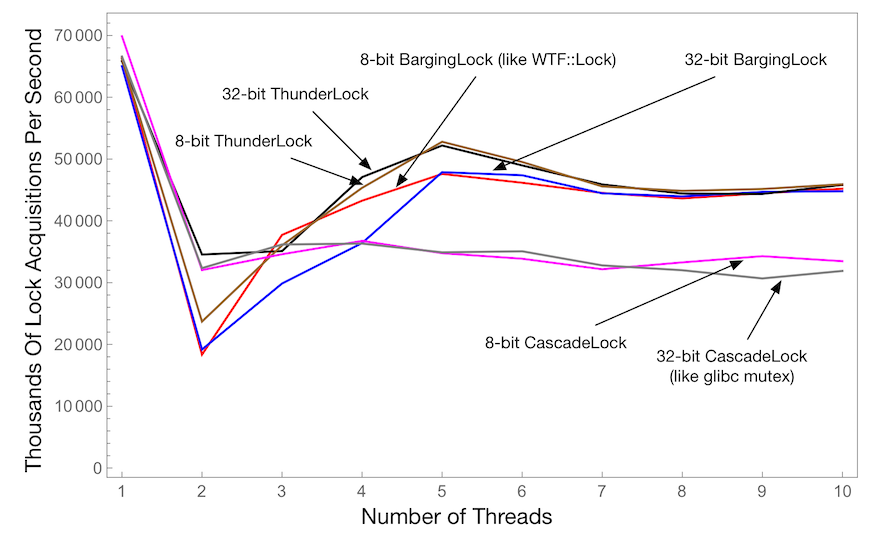
This chart shows the number of successful lock acquisitions per second across all threads as a function of the number of threads. This uses a critical section that does one loop iteration while holding the lock. Higher is better.
This explores three algorithms:
ThunderLock. This unleashes a thundering herd every time it unparks threads.CascadeLock. This is based on glibc’slowlevellockalgorithm.BargingLock. This is likeWTF::Lock, but more configurable.
We then run each one in two variants, one that is 8-bit and one that is 32-bit.
This plot shows that CascadeLock and ThunderLock exhibit wonderful performance for smaller numbers of threads. BargingLock and ThunderLock exhibit the best performance for many threads. This chart suggests that we might have additional performance improvements if we try to take the best of ThunderLock and CascadeLock and integrate them into the WTF::Lock algorithm. On the other hand, this microbenchmark is quite extreme and it doesn’t decisively favor any of these algorithms. Because of these results, we have a bug open about continuing to reconsider our WTF::Lock implementation.
Contention With Different Critical Section Lengths
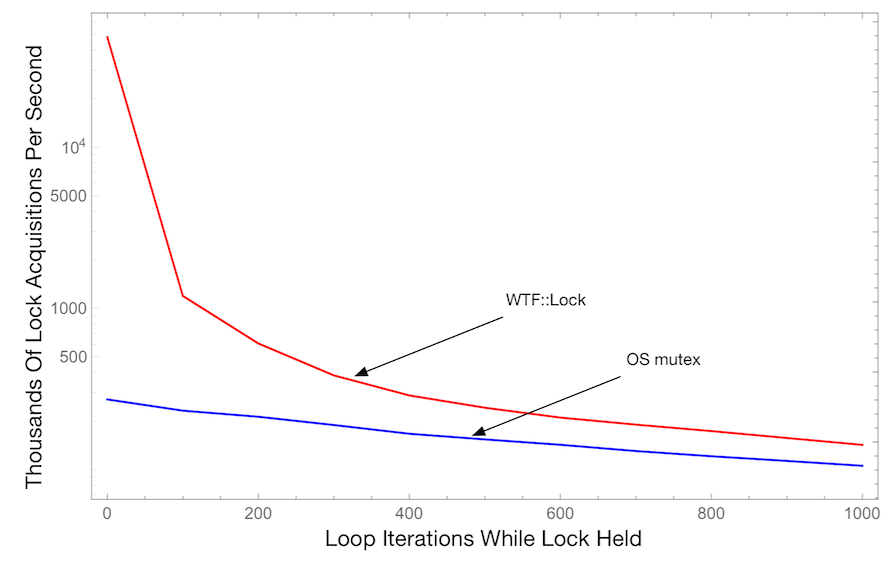
This chart shows the number of successful lock acquisitions per second across all threads as a function of the number of loop iterations while the critical section is held. Higher is better. This uses 4 threads.
All previous microbenchmark charts used a very short critical section. This shows what happens when the critical section length is increased. Unsurprisingly, the performance gap between the OS mutex and WTF::Lock gets reduced, but even for long critical sections (1000 double multiplies and 1000 double adds), WTF::Lock is still almost 2x faster.
Lock Fairness
One advantage of OS mutexes is that they guarantee fairness: All threads waiting for a lock form a queue, and, when the lock is released, the thread at the head of the queue acquires it. It’s 100% deterministic. While this kind of behavior makes mutexes easier to reason about, it reduces throughput because it prevents a thread from reacquiring a mutex it just released. It’s common for WebKit threads to repeatedly acquire the same lock. This section attempts to evaluate the relative fairness of OS mutexes and WTF::Lock.
Our fairness benchmark starts ten threads while a lock is held. It waits a bit after starting them to maximize the likelihood that all of those threads pile up on the lock’s queue. Then we release the lock, and count how many times each thread got to acquire the lock during a 100 millisecond run. A FIFO lock will ensure that each thread got to acquire the lock the same number of times except for an off-by-one step: whenever the 100 millisecond test run finishes, some set of threads may have had a chance to do exactly one more lock acquisition because they happened to come first in the round-robin cycle.
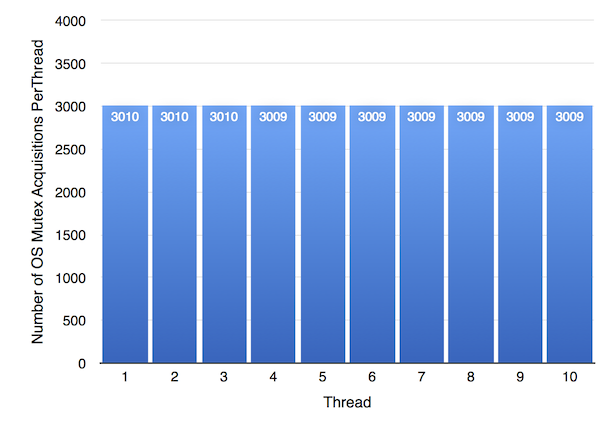
The chart above shows the fairness results for the OS Mutex. As expected, it’s completely fair.
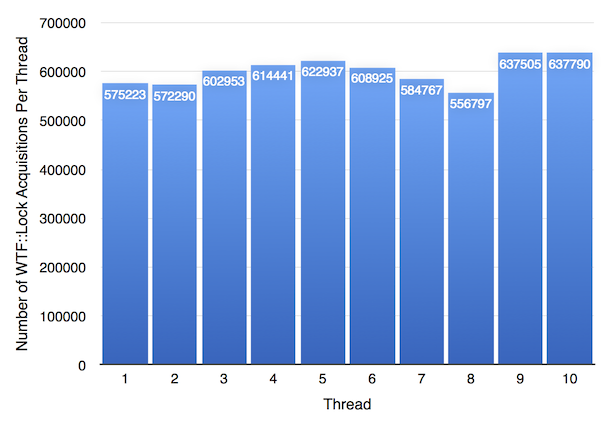
WTF::Lock is slightly less fair according to the chart above. However, the least lucky WTF::Lock thread still got to acquire the lock about 180x more times than any OS Mutex thread: thread 8 was the least lucky WTF::Lock thread with only 556797 acquisitions, 15% less than the thread 10, which was the luckiest. But that’s a huge number of lock acquisitions compared to 3010, the best that the OS mutex threads could do.
This is a surprising result. It’s clear that the OS mutex is doing exactly what it set out to do: no thread gets to do any more work than any other thread. On the other hand, WTF::Lock does not guarantee fairness. Analysis of the algorithm shows that a thread that has been waiting the longest to get the lock may fail to get the lock and be forced to go to the end of the queue. But this chart shows that even without having a fairness guarantee, the unluckiest thread using WTF::Lock got better treatment than any thread using the guaranteed-fair mutex. It’s almost as if the OS mutex is not actually fair because while thread 1 is served equally to thread 2, all 10 threads are underserved relative to a hypothetical thread 11, which is using a different algorithm. Indeed, we can think of thread 11 as being the OS context switch handler.
Fair algorithms make sense in some contexts, like if all critical sections are long and it matters that the longest wait for any thread is bounded by the number of threads and the total length of their critical sections. But WebKit uses tiny critical sections and some of them become contended. The cost of ensuring fairness in small critical sections turns out to be too high to be practical.
We have to account for the possibility that the OS mutex is slower than WTF::Lock for some reason other than fairness. We can test this since we have also implemented HandoffLock, which is a completely fair lock implemented using ParkingLot.
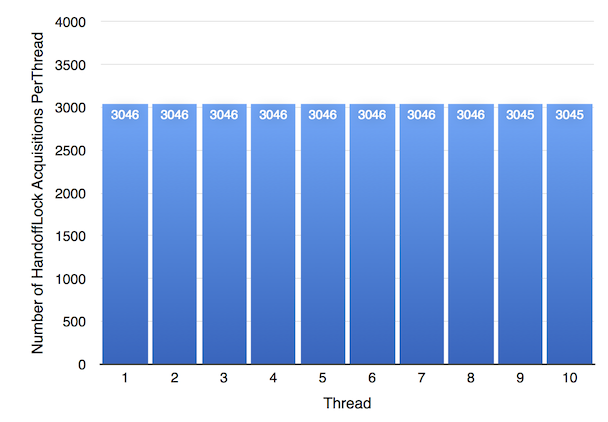
The chart above shows the fairness results for HandoffLock. It performs almost exactly like the OS mutex. This result has some interesting implications. It shows that the OS mutex’s performance is likely to be due entirely to its deterministic fairness guarantee. It also implies that the extra overhead that ParkingLot introduces does not adversely affect the speed with which ParkingLot can handoff execution from one thread to another.
Comparison to Other Novel Locks
The C++ language has a proposed feature called std::synchronic that addresses some of the same problems as ParkingLot. It allows users to write their own locks, and those locks can fit into a small amount of memory. Lock algorithms focus a lot on how to handle contention so as to optimize throughput even when multiple threads want to hold the same lock. An approach for handling contention that is popular in scholarly computer science is transactional memory. If a transactional critical section is contended but the contending threads don’t have any races other than the race to get the lock (i.e. they access disjoint memory except for the lock itself) then these threads will get to run concurrently. If a race is detected, some threads will abort and retry, possibly reverting to a convention lock algorithm. Modern x86 chips support transactional memory via Hardware Lock Elision (HLE). WebKit avoids using a single lock to protect unrelated data, since this is both awkward (it’s easiest to put a tiny WTF::Lock right next to whatever field it protects) and suboptimal (it causes pointless contention). In WebKit we add locks in order to protect data races, so transactions are unlikely to help. This section evaluates the performance of these alternatives, with an emphasis on a WebKit-style critical section, where racing on the lock implies a race for the same underlying data.
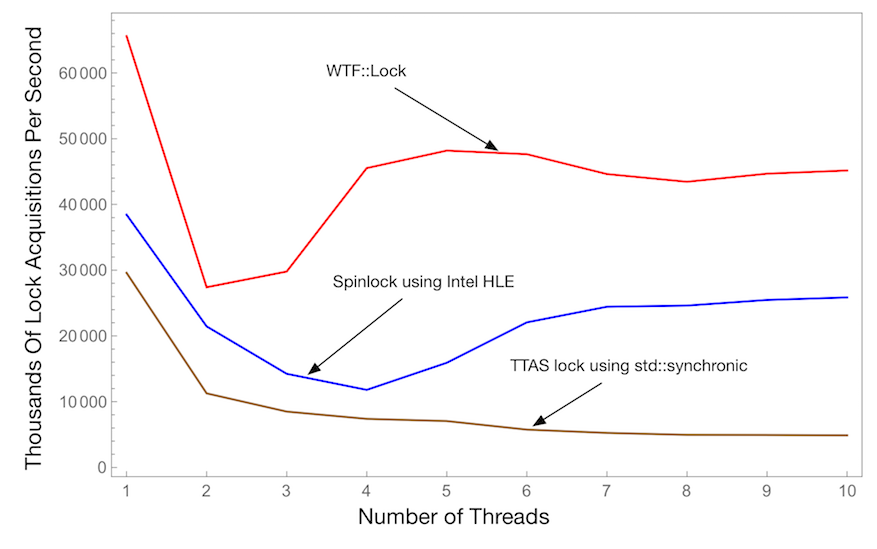
This chart shows the number of successful lock acquisitions per second across all threads as a function of the number of threads. This uses a critical section that does one loop iteration while holding the lock. Higher is better.
To test std::synchronic we implement a lock that follows the “TTAS lock” algorithm in the synchronic test suite. To test HLE, we implement a basic spinlock wrapped with xacquire/xrelease. As this chart shows, WTF::Lock is always significantly faster than either of these kinds of locks. We suspect that std::synchronic performs relatively poorly because it requires the analog of ParkingLot::unparkOne() to run every time a lock is released, even if nobody is waiting. On the other hand, the same features that make std::synchronic a bit slower also make its API a lot easier to use. We suspect that HLE performs relatively poorly because the locks in this benchmark protect a data race. We only use locks in WebKit when there is a data race to protect, so although this benchmark is unfair to the intended use case of HLE, we believe that it’s an appropriate benchmark for simulating how we use locks. We aren’t the first to observe that transactional memory isn’t great. That post observes that one problem with transactional memory is the lack of a killer app, and observes that the industry as a whole is missing a concurrency killer app. WebKit uses concurrency to dramatically speed up JIT compilation and it uses parallelism to dramatically speed up garbage collection, and both are possible thanks to fast locks.
Summary
We replaced all of WebKit’s locks with our own lock implementation, called WTF::Lock. We did this because we wanted to aggressively reduce the sizes of our locks while increasing overall performance. We also wanted the lock to be adaptive, so that threads would not spin when a lock was held for a long time. The new lock, called WTF::Lock is implemented using a reusable abstraction for parking and queuing threads, and that abstraction will come in handy when implementing new web standards.