JSC 💕 ES6
ES2015 (also known as ES6), the version of the JavaScript specification ratified in 2015, is a huge improvement to the language’s expressive power thanks to features like classes, for-of, destructuring, spread, tail calls, and much more. But powerful language features come at a high cost for language implementers. Prior to ES6, WebKit had spent years optimizing the idioms that arise in ES3 and ES5 code. ES6 requires completely new compiler and runtime features in order to get the same level of performance that we have with ES5.
WebKit’s JavaScript implementation, called JSC (JavaScriptCore), implements all of ES6. ES6 features were implemented to be fast from the start, though we only had microbenchmarks to measure the performance of those features at the time. While it was initially helpful to optimize for our own microbenchmarks and microbenchmark suites like six-speed, to truly tune our engine for ES6, we needed a more comprehensive benchmark suite. It’s hard to optimize new language features without knowing how those features will be used. Since we love programming, and ES6 has many fun new language features to program with, we developed our own ES6 benchmark suite. This post describes the development of our first ES6 benchmark, which we call ARES-6. We used ARES–6 to drive significant optimization efforts in JSC, and this post describes three of them: high throughput generators, a new Map/Set implementation, and phantom spread. The post concludes with an analysis of performance data to show how JSC’s performance compares to other ES6 implementations.
ARES-6 Benchmark
The suite consists of two subtests we wrote in ES6 ourselves, and two subtests that we imported that use ES6. The first subtest, named Air, is an ES6 port of the WebKit B3 JIT‘s Air::allocateStack phase. The second subtest, named Basic, is an ES6 implementation of the ECMA-55 BASIC standard using generators. The third subtest, named Babylon, is an import of Babel’s JavaScript parser. The fourth subtest, named ML, is an import of the feedforward neural network library from the mljs machine learning framework. ARES-6 runs the Air, Basic, Babylon, and ML benchmarks multiple times to gather lots of data about how the browser starts up, warms up, and janks up. This section describes the four benchmarks and ARES-6’s benchmark running methodology.
Air
Air is an ES6 reimplementation of JSC’s allocateStack compiler phase, along with all of Assembly Intermediate Representation needed to run that phase. Air tries to faithfully use new features like arrow functions, classes, for-of, and Map/Set, among others. Air doesn’t avoid any features out of fear that they might be slow, in the hope that we might learn how to make those features fast by looking at how Air and other benchmarks use them.
The next section documents the motivation and design of Air. You can browse the source here.
Motivation
At the time that Air was written, most JavaScript benchmarks used ES5 or older versions of the language. ES6 testing mostly relied on microbenchmarks or conversions of existing tests to ES6. We use larger benchmarks to avoid over-optimizing for small pieces of code. We also avoid changing existing benchmarks because that approach has no limiting principle: if it’s OK to change a benchmark to use a feature, does that mean we can also change it to remove the use of a feature we don’t like? We feel that one of the best ways to avoid falling into the trap of creating benchmarks that only reinforce what some JS engine is already good at is to create a new benchmark from first principles.
We only recently completed our new JavaScript compiler, named B3. B3’s backend, named Air, is very CPU-intensive and uses a combination of object-oriented and functional idioms in C++. Additionally, it relies heavily on high speed maps and sets. It goes so far as to use customized map/set implementations – even more so than the rest of WebKit. This makes Air a great candidate for ES6 benchmarking. The Air benchmark in ARES-6 is a faithful ES6 implementation of JSC’s Air. It pulls no punches: just as the original C++ Air was written with expressiveness as a top priority, ES6 Air is liberal in its use of modern ES6 idioms whenever this helps make the code more readable. Unlike the original C++ Air, ES6 Air doesn’t exploit a deep understanding of compilers to make the code easy to compile.
Design
Air runs one of the more computationally expensive C++ Air phases, Air::allocateStack(). It turns abstract stack references into concrete stack references, by selecting how to lay out stack slots in the stack frame. This requires liveness analysis and an interference graph.
Air relies on three major ES6 features more so than most of the others:
- Arrow functions. Like the C++ version with lambdas, Air uses a functional style of iterating most non-trivial data-structures. This is because the functional style allows the callbacks to mutate the data being iterated: if the callback returns a non-null value,
forEachArg()will replace the argument with that value. This would not have been possible with for-of. Air’s use offorEachArg()and arrow functions usually looks like this:
inst.forEachArg((arg, role, type, width) => ...)
- For-of. Many Air data structures are amenable to for-of iteration. While the innermost loops tend to use functional iteration, pretty much all of the outer logic uses for-of heavily. For example:
for (let block of code) // Iterate over the basic blocks in a program
for (let inst of block) // Iterate over the instructions in a block
...
- Map/Set. The liveness analysis in
Air::allocateStack()relies on maps and sets. For example, we use a liveAtHead map that is keyed by basic block. Its values are sets of live stack slots. This is a relatively crude way of doing liveness, but it is exactly how the originalAir::LivenessAnalysisworked. So we view it as being quite faithful to how a sensible programmer might use Map and Set.
Air also uses some other ES6 features. For example, it makes light use of a Proxy. It makes extensive use of classes, let/const, and Symbols. Symbols are used as enumeration elements, and so, they frequently show up as cases in switch statements.
The workflow of an Air run is pretty simple: we do 200 runs of allocateStack on four IR payloads.
Each IR payload is a large piece of ES6 code that constructs an Air Code object, complete with basic blocks, temporaries, stack slots, and instructions. These payloads are generated by running the Air::dumpAsJS() phase. This is a phase we wrote in the C++ version of Air that will generate JS code that builds an IR payload. Just prior to running the C++ allocateStack phase, we perform Air::dumpAsJS() to capture the payload. The four payloads we generate are for the hottest functions in four other major JS benchmarks:
- Octane/GBEmu, the
executeIterationfunction. - Kraken/imaging-gaussian-blur, the
gaussianBlurfunction. - Octane/Typescript, the
scanIdentifierfunction. - Air (yes, it’s self referential), an anonymous closure identified by our profiler as
ACLj8C.
These payloads allow Air to precisely replay allocateStack on those actual functions.
Air validates its results. We added a Code hashing capability to both the C++ Air and ES6 Air, and we assert each payload looks identical after allocateStack to what it would have looked like after the original C++ allocateStack. We also validate that the payloads hash properly before allcoateStack, to help catch bugs during payload initialization. We have not measured how long hashing takes, but it’s an O(N) operation, while allocateStack is closer to O(N^2). We suspect that barring some engine pathologies, hashing should be much faster than allocateStack, and allocateStack should be where the bulk of time is spent.
Summary
At the time that Air was written, we weren’t happy with the ES6 benchmarks that were available to us. Air makes extensive use of ES6 features in the hope that we can learn about possible optimization strategies by looking at this and other benchmarks.
Air does not use generators at all. We almost used them for forEachArg iteration, but it would have been a very unusual use of generators because Air’s forEach functions are more like map than for-of. The whole point is to allow the caller to mutate entries. We thought that functional iteration was more natural for this case than for-of and generators. But this led us to wonder: how would we use generators?
Basic
Web programming requires reasoning about asynchrony. But back when some of us first learned to program with the BASIC programming language, we didn’t have to worry about that: if you wanted input from the user, you said INPUT and the program would block until the user typed things. In a sense, this is what generators are about: when you say yield, your code blocks until some other stuff happens.
Basic is an ES6 implementation of ECMA-55 BASIC. It implements the interpreter as a recursive abstract syntax tree (AST) walk, where the recursive functions are generators so that they can yield when they encounter BASIC’s INPUT command. The lexer is also written as a generator. Basic tests multiple styles of generators, including functions with multiple yield points and recursive yield* calls.
The next section describes how Basic uses generators in the lexer and in the AST walk. You can browse the source here.
Lexer
Lexers are usually written as a lex function that maintains some state and returns the next token whenever you call it. Basic uses a generator to implement lex, so that it can use local variables for all of its state.
Basic’s lexer is a generator function with multiple nested functions inside it. It contains eight uses of yield, none of which are recursive.
AST Walk
Walking the AST is an easy way to implement an interpreter and this was a natural choice for Basic. In such a scheme, the program is represented as a tree, and each node has code associated with it that may recursively invoke sub-nodes in the tree. Basic uses plain object literals to create nodes. For example:
{evaluate: Basic.NumberPow, left: primary, right: parsePrimary()}
This code in the parser creates an AST node whose evaluation function is Basic.NumberPow. Were it not for INPUT, Basic could use ordinary functions for all of the AST. But INPUT requires blocking; so, we implement that with yield. This means that all of the statement-level AST nodes use generators. Those generators may call each other recursively using yield*.
The AST walk interpreter contains 18 generator functions with two calls to yield (in INPUT and PRINT) and one call to yield* (in Basic.Program).
Workloads
Each Basic benchmark iteration runs five simple Basic programs:
- Hello world!
- Print numbers 1..10.
- Print a random number.
- Print random numbers until 100 is printed.
- Find all prime numbers from 2 to 1999.
The interpreter uses a fixed seed, so the random parts always behave the same way. The Basic benchmark runs 200 iterations.
Summary
We wrote Basic because we wanted to see what an aggressive attempt at using generators looks like. Prior to Basic, all we had were microbenchmarks, which we feared would focus our optimization efforts only on the easy cases. Basic uses generators in some non-obvious ways, like having multiple generator functions, many yield points, and recursive generator calls. Basic also uses for-of, classes, Map, and WeakMap.
Babylon and ML
It is important to us that ARES-6 consists both of tests we wrote, and tests we imported. Babylon and ML are two tests we imported with minor modifications to make them run in the browser without Node.js style modules or ES6 modules. (The reason for not including tests with ES6 modules is that at the time of writing this, <script type="module"> is not on by default in all major browsers.) Writing new tests for ARES-6 is important because it allows us to use ES6 in interesting and sophisticated ways. Importing programs we didn’t write is also imperative for performance analysis because it ensures that we measure the performance of interesting programs already using ES6 out in the wild.
Babylon is an interesting test for ARES-6 because it makes light use of classes. We think that many people will dip their toes into ES6 by adopting classes since many ES5 programs are written in ways that lead to an easy translation to classes. We’ve seen this firsthand in the WebKit project when Web Inspector moved all their ES5 pseudo-classes to use ES6 class syntax. You can browse the Babylon source in ARES-6 here. The Babylon benchmark runs 200 iterations where each iteration consists of parsing four JS programs.
The feedforward neural network library, that the ML benchmark is imported from, depends heavily on ES6 classes. It uses the ml-matrix library which implements matrix manipulations in a decidedly object oriented style using ES6 classes almost exclusively. You can browse the ML source in ARES-6 here. The ML benchmark runs 60 iterations where each iteration consists of performing analysis over different sample data sets using various activation functions.
Benchmarking Methodology
Air, Basic and Babylon each run for 200 iterations, and ML runs for 60 iterations. Each iteration does the same kind of work. We simulate page reload before the first of those iterations, to minimize the chances that the code will benefit from JIT optimizations at the beginning of the first iteration. ARES-6 analyzes these four benchmarks in three different ways:
- Start-up performance. We want ES6 code to run fast right from the start, even if our JITs haven’t had a chance to perform optimizations yet. ARES-6 reports a First Iteration score that is just the execution time of the first of the 60 or 200 iterations.
- Worst-case performance. JavaScript engines have a lot of different kinds of jank. The GC, JIT, and various adaptive optimizations all run the risk of causing programs to sometimes run for much longer than the norm. We don’t want our ES6 optimizations to introduce new kinds of jank. ARES-6 reports a Worst 4 Iterations score that is the average of the execution times of the worst 4 of the 60 or 200 iterations, excluding the first iteration which was used for measuring start-up performance.
- Throughput. If you write some ES6 code and it runs for long enough, then it should eventually benefit from all of our optimizations. ARES-6 reports an Average score that is the average execution time of all iterations excluding the first.
Each repetition of ARES-6 yields 3 scores (measured in milliseconds): First Iteration, Worst 4 Iterations, and Average, for each of the 4 subtests: Air, Basic, Babylon, and ML, for a total of 12 scores. The geometric mean of all 12 scores is the Overall score for the repetition. ARES-6 runs 6 repetitions, and reports the averages of each of these 13 scores along with their 95% confidence intervals. Since these scores are measures of execution time, lower scores are better because they mean that the benchmark completed in less time.
Optimizations
We built ARES-6 so that we could have benchmarks with which to tune our ES6 implementation. ARES-6 was built specifically to allow us to study the impact of new language features on our engine. This section describes three areas where we made significant changes to JavaScriptCore in order to improve our score on ARES-6. We revamped our generator implementation to give generator functions full access to our optimizing JITs. We rewrote our Map/Set implementation so that our JIT compiler can inline Map/Set lookups. Finally, we added significant new escape analysis functionality to eliminate the object allocation of the rest parameter when used with the spread operator.
High-Throughput Generators
The performance of ES6 generators is critical to the overall performance of JavaScript engines. We expect generators to be frequently used as ES6 adoption increases. Generators are a language-supported way to suspend and resume an execution context. They can be used to implement value streams and custom iterators, and are the basis of ES2017’s async and await, which streamlines the notoriously tricky asynchronous Promise programming model into the direct style programming model. To be performant, it was an a priori goal that our redesigned generator implementation had a sound and simple compilation strategy in all of our JIT tiers.
A generator must suspend and resume the execution context at the point of a yield expression. To do this, JSC needs to save and restore its execution state: the instruction pointer and the current stack frame. While we need to save the logical JavaScript instruction pointer to resume execution at the appropriate point in the program, the machine’s instruction pointer may change. If the function is compiled in upper JIT tiers (like baseline, DFG, and FTL), we must select the code compiled in the best tier when resuming. In addition, the instruction pointer may be invalidated if the compiled code is deoptimized.
JSC’s bytecode is a 3AC-style (three-address code) IR (intermediate representation) that operates over virtual registers. The bytecode is allowed an effectively “infinite” number of registers, and the stack frame comprises slots to store each register. In practice, the number of virtual registers used is small. The key insight into our generator implementation is that it is a transformation over JSC’s bytecode. This completely hides the complexity of generators from the rest of the engine. The phases prior to bytecode generatorification (parsing, bytecode generation from the AST) are allowed to view yield as if it were a function call — about the easiest kind of thing for those phases to do. Best of all, the phases after generatorification do not have to know anything about generators. That’s a fantastic outcome, since we already have a massive interpreter and JIT compiler infrastructure that consumes this bytecode.
When generating the original bytecode, JSC’s bytecode compiler treats a generator mostly as if it were a program with normal control flow, where each “yield” point is simply an expression that takes arguments, and results in a value. However, this is not how yield is implemented at a machine level. To transform this initial form of bytecode into a version that does proper state restoration, we rewrite the generator’s bytecode to turn the function into a state machine.
To properly restore the instruction pointer at yield points, our bytecode transformation inserts a switch statement at the top of each generator function. It performs a switch over an integer that represents where in the program the generator should resume when called. Secondly, we must have a way to restore each virtual register at each yield point. It turns out that JSC already has a mechanism for doing exactly this. We turned this problem into a problem of converting each bytecode virtual register in the original bytecode into a closure variable in JSC’s environment record data structure. Each transformed generator allocates a closure to store all generator state. Every yield point saves each live virtual register into the closure, and every resume point restores each live virtual register from the closure.
Because this bytecode transformation changes the program only by adding closures and a switch statement, this approach trivially meets our goal of being compilable in our optimizing compiler tiers. JSC’s optimizing compilers already do a good job at optimizing switch statements and closure variables. The generator’s dispatch gets all of JSC’s switch lowering optimizations just by virtue of using the switch bytecode. This includes our B3 JIT’s excellent switch lowering optimization, and less aggressive versions of that same optimization in lower JIT tiers and in the interpreter. The DFG also has numerous optimizations for closures. This includes inferring types of closure variables, optimizing loads and stores to closures down to a single instruction in most cases, and properly modeling the aliasing effects of closure accesses. We get these benefits without introducing new constructs into the optimizing compiler.
Example
Let’s walk through an example of the bytecode transformation for an example JavaScript generator function:
function *generator()
{
var temp = 20;
var result = yield 42;
return result + temp;
}
JSC generates the bytecode sequence shown in the following figure, which represents the control flow graph.

When the AST-to-bytecode compiler sees a yield expression, it just emits the special op_yield bytecode operation. This opcode is a macro. It’s not recognized by any of our execution engines. But it has well-understood semantics, which allows us to treat it as bytecode syntactic sugar for closures and switches.
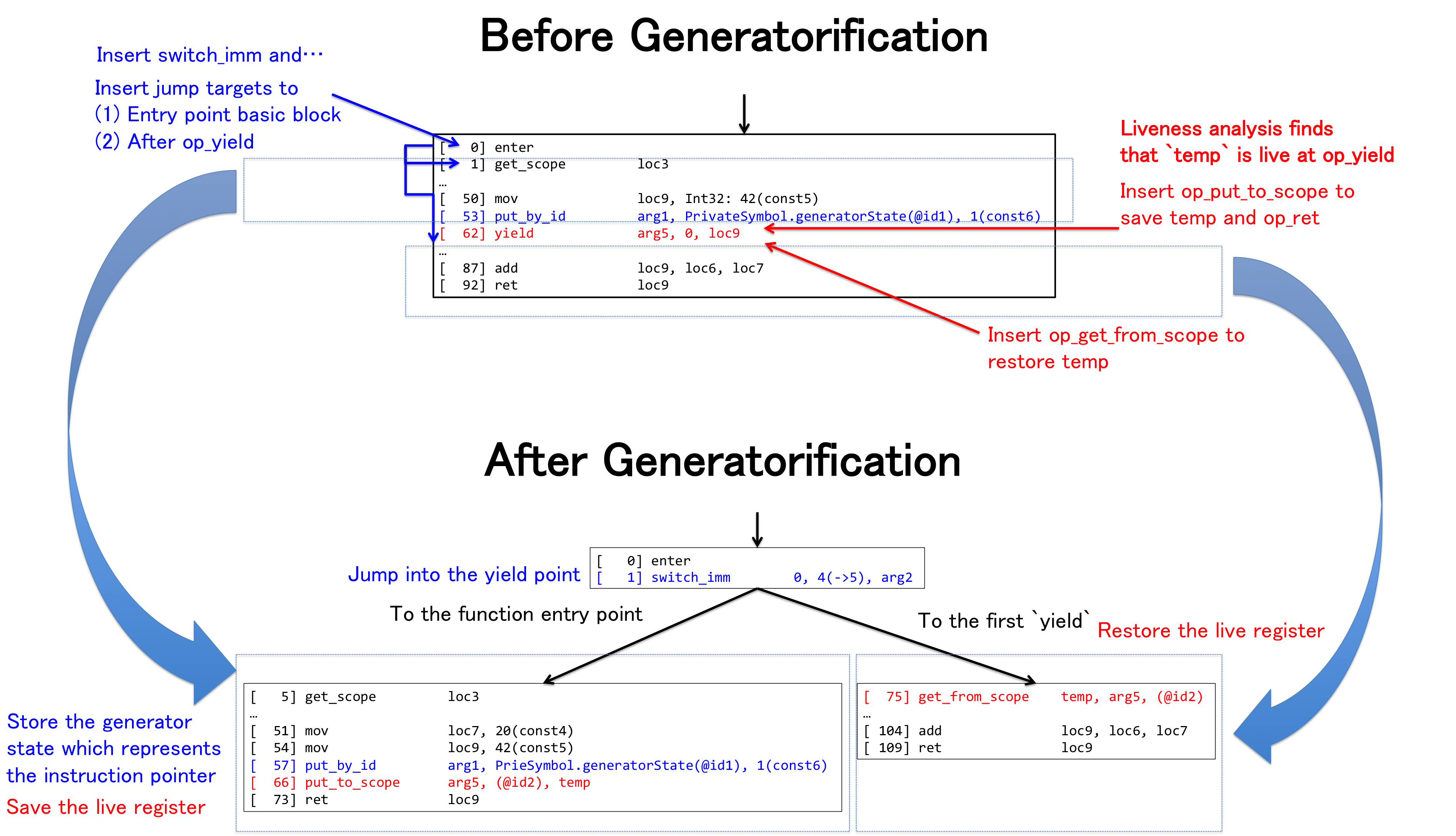
Desugaring is performed by the generatorification bytecode phase. The figure above explains how generatorification works. Generatorification rewrites the bytecode so that there are no more op_yield statements and the resulting function selects which code to execute using a switch statement. Closure-style property access bytecodes are used to save/restore state around where the op_yield statements used to be.
Previously, JSC bytecode was immutable. It was used to carry information from the bytecode generator, which wrote bytecode as a byproduct of walking the AST, to the compilers, which would consume it to create some other byproduct (either machine code or some other compiler IR). Generatorification changes that. To facilitate this phase, we created a general-purpose bytecode rewriting facility for JSC. It allows us to insert and remove any kind of bytecode instruction, including jumps. It permits us to perform sophisticated control-flow edits on the bytecode stream. We use this to make generatorification easier, and we look forward to using it to implement other crazy future language features.
To allow suspension and resumption of the execution context at op_yield, the rewriter inserts the op_switch_imm opcode just after the op_enter opcode. At the point of op_yield, the transformed function saves the integer that represents the virtual instruction pointer and then returns from the function with op_ret. Then, when resuming, we use the inserted op_switch_imm with the saved integer, jumping to the point just after the op_yield which suspended the context.
To save and restore live registers, this pass performs liveness analysis to find live registers at op_yield and then inserts op_put_to_scope and op_get_from_scope operations to save their state and restore it (respectively). These opcodes are part of our closure object model, which happens to be appropriate here because JSC’s closures are just objects that statically know what their fields are and how they will be laid out. This allows fast allocation and fast access, which we already spent a great deal of time optimizing for actual JS closures. In this figure, generatorification performs liveness analysis and finds that the variable temp is live over the op_yield point. Because of this, the rewriter emits op_put_to_scope and op_get_from_scope to save and restore temp. This does not disrupt our optimizing compiler’s ability to reason about temp‘s value, since we had already previously solved that same problem for variables saved to closures.
Summary
The generatorification rewrite used bytecode desugaring to encapsulate the whole idea of generators into a bytecode phase that emits idiomatic JSC bytecode. This allows our entire optimization infrastructure to join the generator party. Programs that use generators can now run in all of our JIT tiers. At the time this change landed, it sped up Basic’s Average score by 41%. It also improved Basic overall: even the First Iteration score got 3% faster, since our low-latency DFG optimizing JIT is designed to provide a boost even for start-up code.
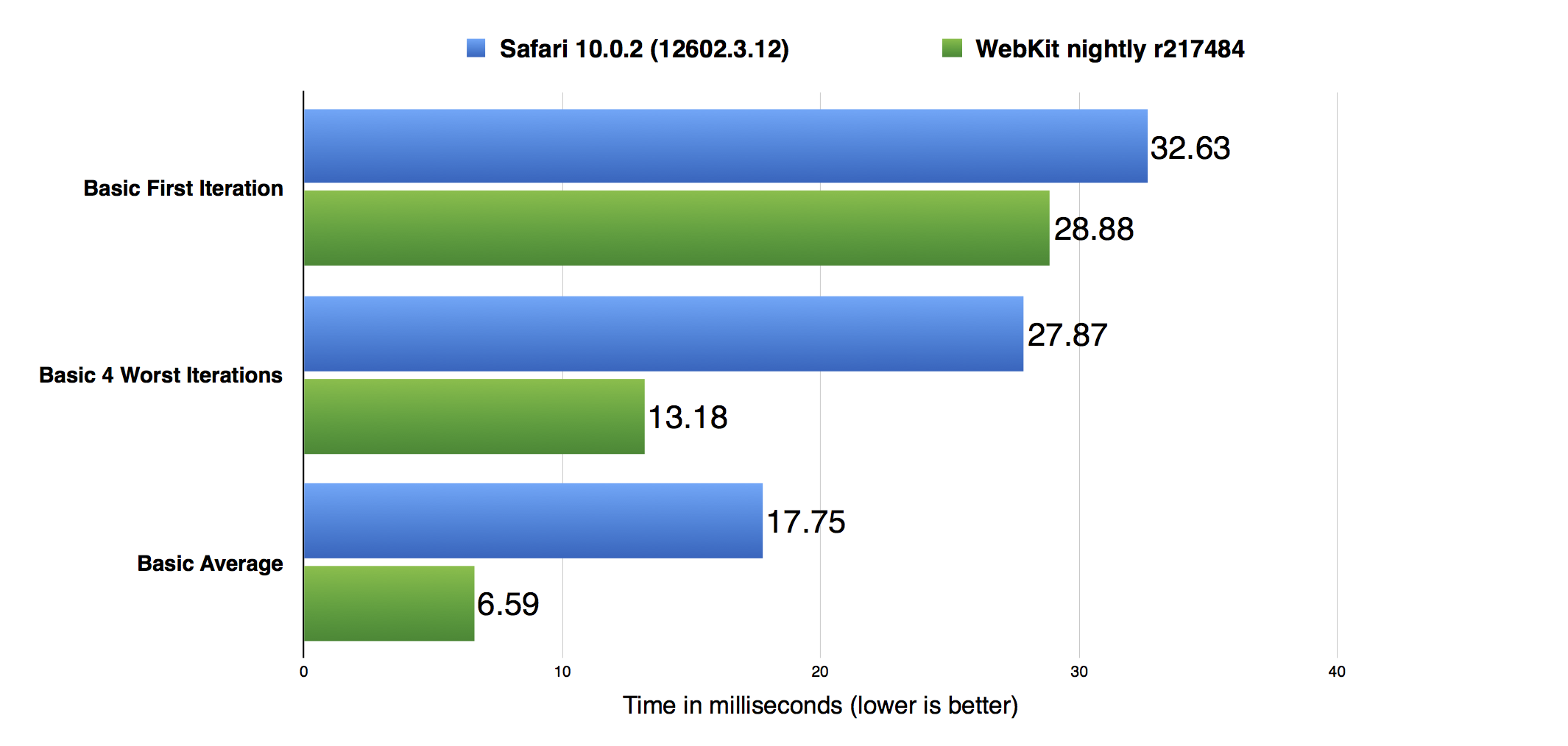
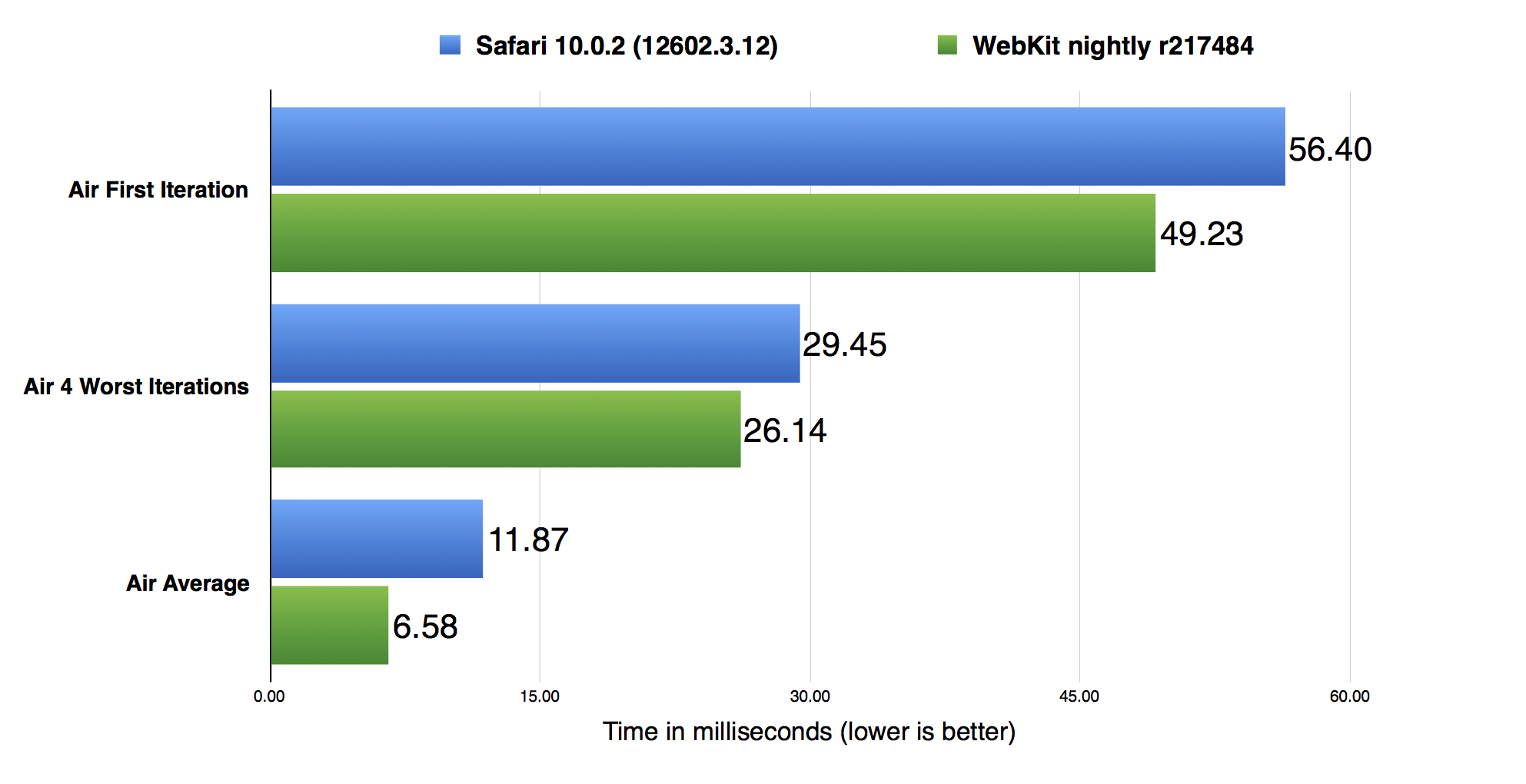
The data in the above graph was taken on a Mid 2014, 2.8 GHz Core i7, 16GB RAM, 15″ MacBook Pro, running macOS Sierra version 10.12.0. Safari 10.0.2 is the first version of Safari to ship with JavaScriptCore’s complete ES6 implementation. Safari 10.0.2 does not include any of the optimizations described in this post. The above graph shows that since implementing ES6, we’ve made significant improvements to JSC’s performance running Basic. We’ve made a 1.2x improvement in the First Iteration score, a 1.4x improvement in the Worst 4 Iterations score, and a 2.8x improvement in the Average score.
Desugaring is a classic technique. Crazy compiler algorithms are easiest to think about when they are confined to their own phase, so we turned our bytecode into a full-fledged compiler IR and implemented generatorification as a compiler phase over that IR. Our new bytecode rewriter is powerful enough to support many kinds of phases. It can insert and remove any kind of bytecode instruction including jumps, allowing for complex control flow edits. While it’s only used for generators presently, this rewriting facility can be used to implement complex ECMAScript features in the future.
Fast Map and Set
Map and Set are two new APIs in ES6 that make it a more expressive language to program in. Prior to ES6, there was no official hashtable API for JavaScript. It’s always been possible to use a JavaScript object as a hashtable if only Strings and Symbols are used as keys, but this isn’t nearly as useful as a hashtable that can take any value as a key. ES6 fixes this ancient language deficiency by adding new Map and Set types that accept any JavaScript value as a key.
Both Air and Basic use Map and Set. Profiling showed that iteration and lookup were by far the most common operations, which is fairly consistent with our experience elsewhere in the language. For example, we have always found it more important to optimize property loads than property stores, because loads are so much more common. In this section we present our new Map/Set implementation, which we optimized for the iteration and lookup patterns of ARES-6.
Fast Lookup
To make lookup fast, we needed to teach our JIT compilers about the internal workings of our hashtable. The main performance benefit of doing this comes from inlining the hashtable lookup into the IR for a function. This obviates the need to call out to C++ code. It also allows us to implement the lookup more efficiently by leveraging the compiler’s smarts. To understand why, let’s analyze a hashtable lookup in more detail. JSC’s hashtable implementation is based off the linear probing algorithm. When you perform map.has(key) inside a JS program, we’re really performing a few abstract operations under the hood. Let’s break those operations down into pseudo code:
let h = hash(key);
let bucket = map.findBucket(h);
let has = !isEmptyBucket(bucket);
return has;
You can think of the findBucket(h) operation as:
let bucket = startBucket(h);
while (true) {
if (isEmptyBucket(bucket))
return emptyBucketSentinel;
// Note that the actual key comparison for ES6 Map and Set is not triple equals.
// But it's close. We can assume it's triple equals for the sake of this explanation.
if (bucket.key === key)
return bucket;
h = nextIndex(h);
}
There are many things that can be optimized here based on information we have about key. The compiler will often know the type of key, allowing it to emit a more efficient hash function, and a more efficient triple equals comparison inside the findBucket loop. The C code must handle JavaScript key values of all possible types. However, inside the compiler, if we know the type of key, we may be able to emit a triple equals comparison that is only a single machine compare instruction. The hash function over key also benefits from knowing the type of key. The C++ implementation of the hash function must handle keys of all types. This means that it’ll have to do a series of type checks on key to determine how it should be hashed. The reason for this is we hash numbers differently than strings, and differently than objects. The JIT compiler will often be able to prove the type of key, thereby allowing us to avoid multiple branches to learn key‘s type.
These changes alone already make Map and Set much faster. However, because the compiler now knows about the inner workings of a hashtable, it can further optimize code in a few neat ways. Let’s consider a common use of the Map API:
if (map.has(key))
return map.get(key);
...
To understand how our compiler optimizations come into play, let’s look at how our DFG (Data Flow Graph) IR represents this program. DFG IR is used by JSC for performing high-level JavaScript-specific optimizations, including optimizations based on speculation and self-modifying code. This hashtable program will be transformed into roughly the following DFG IR (actual DFG IR dumps have a lot more information):
BasicBlock #0:
k: GetArgument("key")
m: GetArgument("map")
h: Hash(@k)
b: GetBucket(@m, @h, @k)
c: IsNonEmptyBucket(@b)
Branch(@c, True:#1, False:#2)
BasicBlock #1:
h2: Hash(@k)
b2: GetBucket(@m, @h2, @k)
r: LoadFromBucket(@b2)
Return(@r)
BasicBlock #2:
...
DFG IR allows for precise modeling of effects of each operation as part of the clobberize analysis. We taught clobberize how to handle all of our new hashtable operations, like GetBucket, IsNonEmptyBucket, Hash, and LoadFromBucket. The DFG CSE (common subexpression elimination) phase uses this data and runs with it: it can see that the same Hash and GetBucket operations are performed twice without any operations that could change the state of the map in between them. Lots of other DFG phases use clobberize to understand the aliasing and effects of operations. This unlocks loop-invariant code motion and lots of other optimizations.
In this example, the optimized program will look like:
BasicBlock #0:
k: GetArgument("key")
m: GetArgument("map")
h: Hash(@k)
b: GetBucket(@m, @h, @k)
c: IsNonEmptyBucket(@b)
Branch(@c, True:#1, False:#2)
BasicBlock #1:
r: LoadFromBucket(@b)
Return(@r)
BasicBlock #2:
...
Our compiler was able to optimize the redundant hashtable lookups in has and get down to a single lookup. In C++, hashtable APIs go to great lengths to provide ways of avoiding redundant lookups like the one here. Since ES6 provides only very simple Map/Set APIs, it’s difficult to avoid redundant lookups. Luckily, our compiler will often get rid of them for you.
Fast Iteration
As we wrote Basic and Air, we often found ourselves iterating over Maps and Sets because writing such code is natural and convenient. Because of this, we wanted to make Map and Set iteration fast. However, it’s not immediately obvious how to do this because ES6’s Map and Set iterate over keys in insertion order. Also, if a Map or Set is modified during iteration, the iterator must reflect the modifications.
We needed to use a data structure that is fast to iterate over. An obvious choice is to use a linked list. Iterating a linked list is fast. However, testing for the existence of something inside a linked list is O(n), where n is the number of elements in the list. To accommodate the fast lookup of a hashtable, and the fast iteration of a linked list, we chose a hybrid approach of a combo linked-list hashtable. Every time something is added to a Map or Set, it goes onto the end of the linked list. Every element in the linked list is a bucket. Each entry in the hashtable’s internal lookup buffer points to a bucket inside the linked list.
This is best understood through a picture. Consider the following program:
let map = new Map;
map.set(1, "one");
map.set(2, "two");
map.set(3, "three");
A traditional linear probing hashtable would look like this:
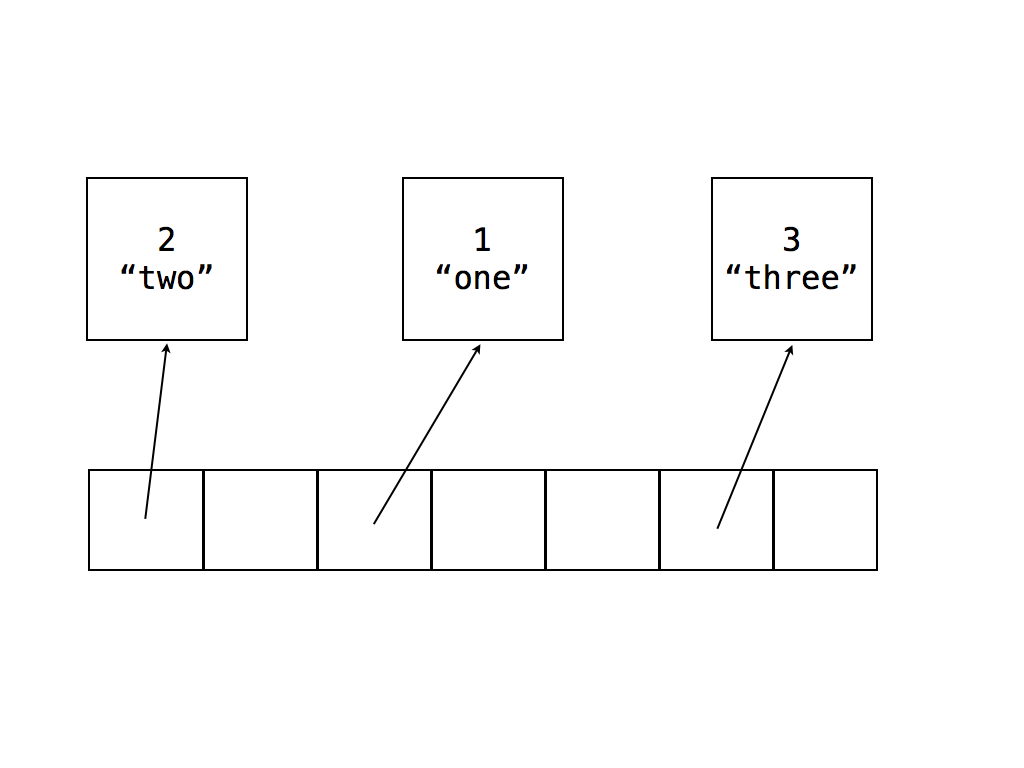
However, in our scheme, we need to know the order in which we need to iterate the hashtable. So, our combo linked-list hashtable will look like this:
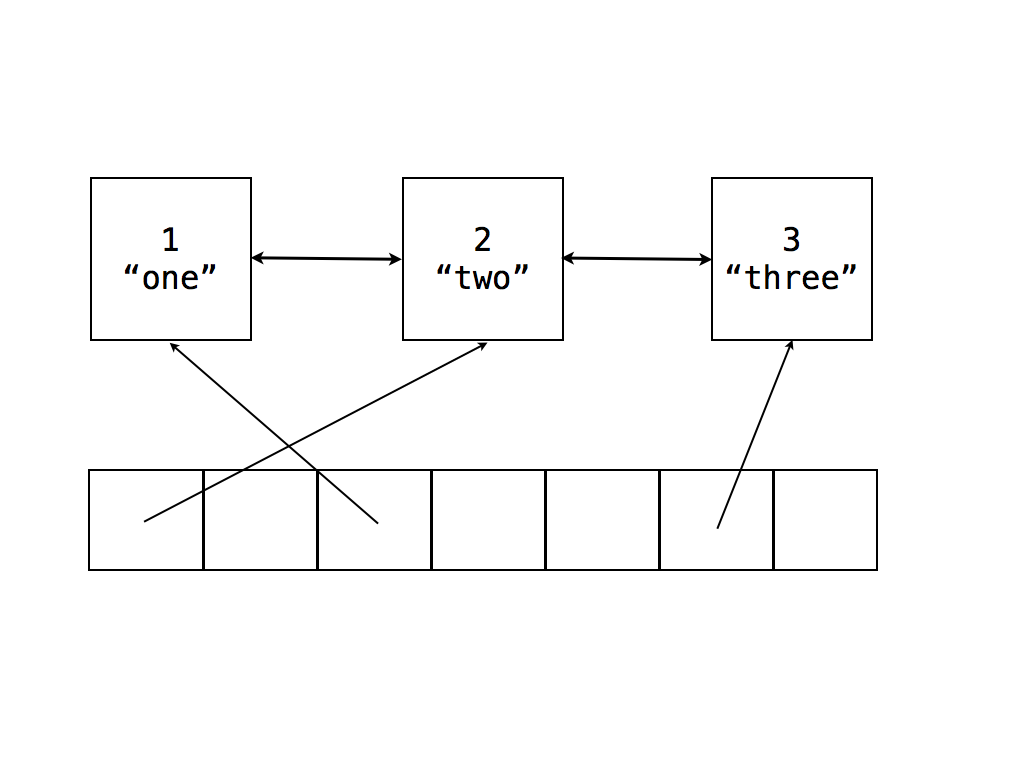
As mentioned earlier, when iterating over a Map or Set while changing it, the iterator must iterate over newly added values, and must not iterate over deleted values. Using a linked list data structure for iteration allows for a natural implementation of this requirement. Inside JSC, Map and Set iterators are just wrappers over hashtable buckets. Buckets are garbage collected, so an iterator can hang onto a bucket even after it has been removed from the hashtable. As an item is deleted from the hashtable, the bucket is removed from the linked list by updating the deleted bucket’s neighbors to now point to each other instead of the deleted bucket. Crucially, the deleted bucket will still point to its neighbors. This allows iterator objects to still point to the deleted bucket and then find their way back to non-deleted buckets. Asking such an iterator for its value will lead the iterator to traverse its neighbor pointer until it finds the next non-deleted bucket. The key insight here is that deleted buckets can always find the next non-deleted bucket by doing a succession of pointer chasing through their neighbor pointer. Note that this pointer chasing might lead the iterator to the end of the list, in which case, the iterator is closed.
For example, consider the previous program, now with the key 2 deleted:
let map = new Map;
map.set(1, "one");
map.set(2, "two");
map.set(3, "three");
map.delete(2);
Now, the hashtable will look like this:
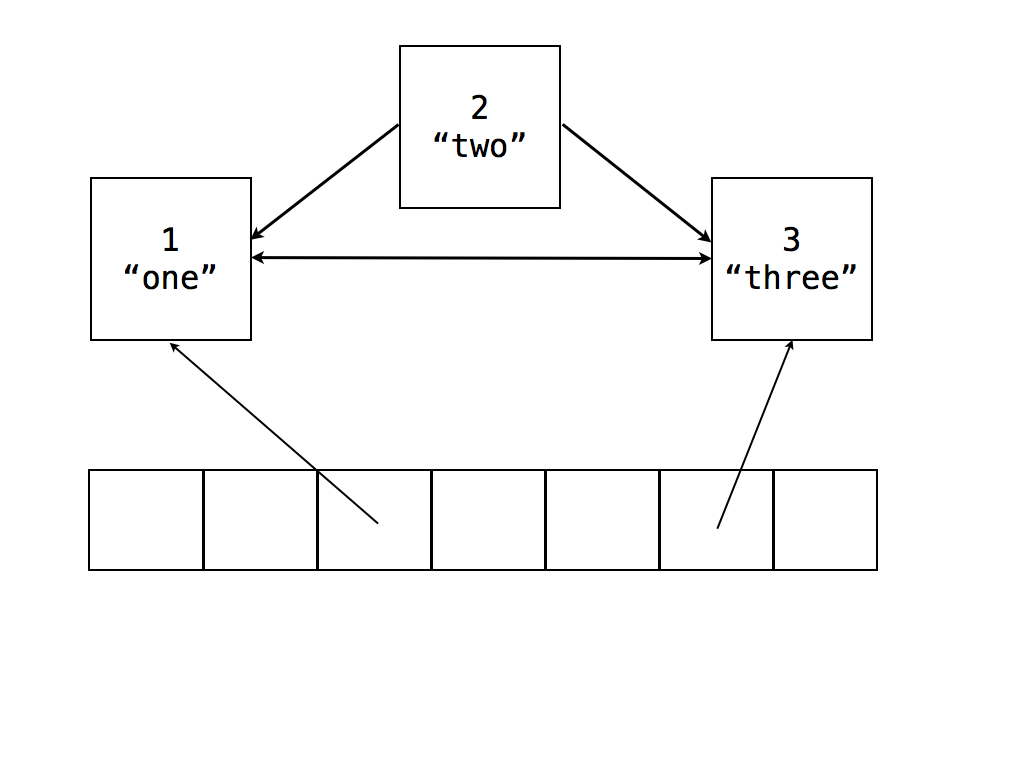
Let’s consider what happens when there is an iterator that’s pointing to the bucket for 2. When next() is called on that iterator, it’ll first check if the bucket it’s pointing to is deleted, and if so, it will traverse the linked list until it finds the first non-deleted entry. In this example, the iterator will notice the bucket for 2 is deleted, and it will traverse to the bucket for 3. It will see that 3 is not deleted, and it will yield its value.
Summary
We found ourselves using Map/Set a lot in the ES6 code that we wrote, so we decided to optimize these data structures to further encourage their use. Our Map/Set rewrite represents the hashtable’s underlying data structures in a way that is most natural for our garbage collector and DFG compiler to reason about. At the time this rewrite was committed, it contributed to an 8% overall performance improvement on ARES-6.
Phantom Spread
Another ES6 feature we found ourselves using is the combination of the rest parameter and the spread operator. It’s an intuitive programming pattern to gather some arguments into an array using the rest parameter, and then forward them to another function call using spread. For example, here is one way we use this in the Air benchmark:
visitArg(index, func, ...args)
{
let replacement = func(this._args[index], ...args);
if (replacement)
this._args[index] = replacement;
}
A naive implementation of spread over the rest parameter will cause this code to run slower than needed because a spread operator requires performing the iterator protocol on its argument. Because the function visitArg is creating the args array, the DFG compiler knows exactly what data will be stored into it. Specifically, it’ll be filled with all but the first two arguments to visitArg. We chose to implement an optimization for this programming pattern because we think that the spread of a rest parameter will become a common ES6 programming idiom. In JSC, we also implement an optimization for the ES5 variant of this programming idiom:
foo()
{
bar.apply(null, arguments);
}
The ideal code the DFG could emit to set up the stack frame for the call to func inside visitArg is a memcpy from the arguments on its own stack frame to that of func‘s stack frame. To be able to emit such code, the DFG compiler must prove that such an optimization is sound. To do this, the DFG must prove a few things. It must first ensure that the array iterator protocol is not observable. It proves it is not observable by ensuring that:
Array.prototype[Symbol.iterator]is its original value,- Array Iterator Prototype’s
nextfunction is its original value.
By performing such a proof, the DFG knows exactly what the protocol will do and it can model its behavior internally. Secondly, the DFG must prove that the args array hasn’t changed since being populated with the values from the stack. It does this by performing an escape analysis. The escape analysis will give a conservative answer to the question: has the args array changed since its creation on entry to the function? If the answer to the question is “no”, then the DFG does not need to allocate the args array. It can simply perform a memcpy when setting up func‘s stack frame. This is a huge speed improvement for a few reasons. The primary speed gain is from avoiding performing the high-overhead iterator protocol. The secondary improvement is avoiding a heap object allocation for the args array. When the DFG succeeds at performing this optimization, we say it has converted a Spread into a PhantomSpread. This optimization leverages the DFG’s ability to not only optimize away object allocations, but to rematerialize them if speculative execution fails and we fall back to executing the bytecode without optimizations.
The data in the above graph was taken on a Mid 2014, 2.8 GHz Core i7, 16GB RAM, 15″ MacBook Pro, running macOS Sierra version 10.12.0. PhantomSpread was a significant new addition to our DFG JIT compiler. The Phantom Spread optimization, the rewrite of Map/Set, along with other overall JSC improvements, shows that we’ve sped up Air’s Average score by nearly 2x since Safari 10.0.2. Crucially, we did not introduce such a speed up at the expense of the First Iteration and Worst 4 Iterations scores. Both of those scores have also progressed.
Performance Results
We believe that a great way to keep ourselves honest about JavaScriptCore’s performance is to compare to the best performance baselines available. Therefore, we routinely compare our performance both to past versions of JavaScriptCore and to other JavaScript engines. This section shows how JavaScriptCore compares to Firefox and Chrome’s JavaScript engines.
The graphs in this section use data taken on a Late 2016, 2.9 GHz Core i5, 8GB RAM, 13″ MacBook Pro, running macOS High Sierra Beta 1.
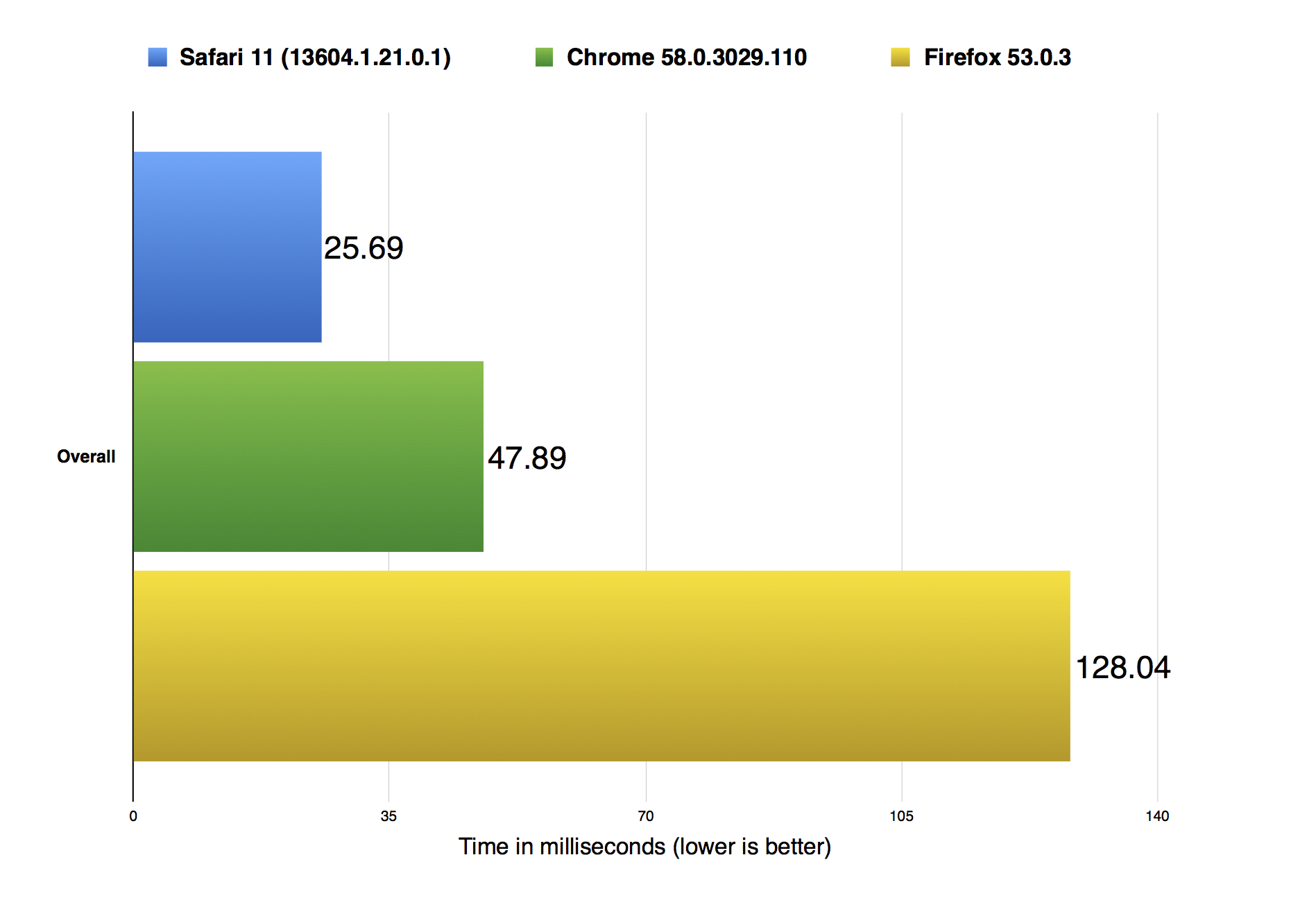
The figure above shows the overall ARES-6 scores in three different browsers: Safari 11 (13604.1.21.0.1), Firefox 53.0.3, and Chrome 58.0.3029.110. Our data shows that we’re nearly to 1.8x faster than Chrome, and close to 5x faster than Firefox.
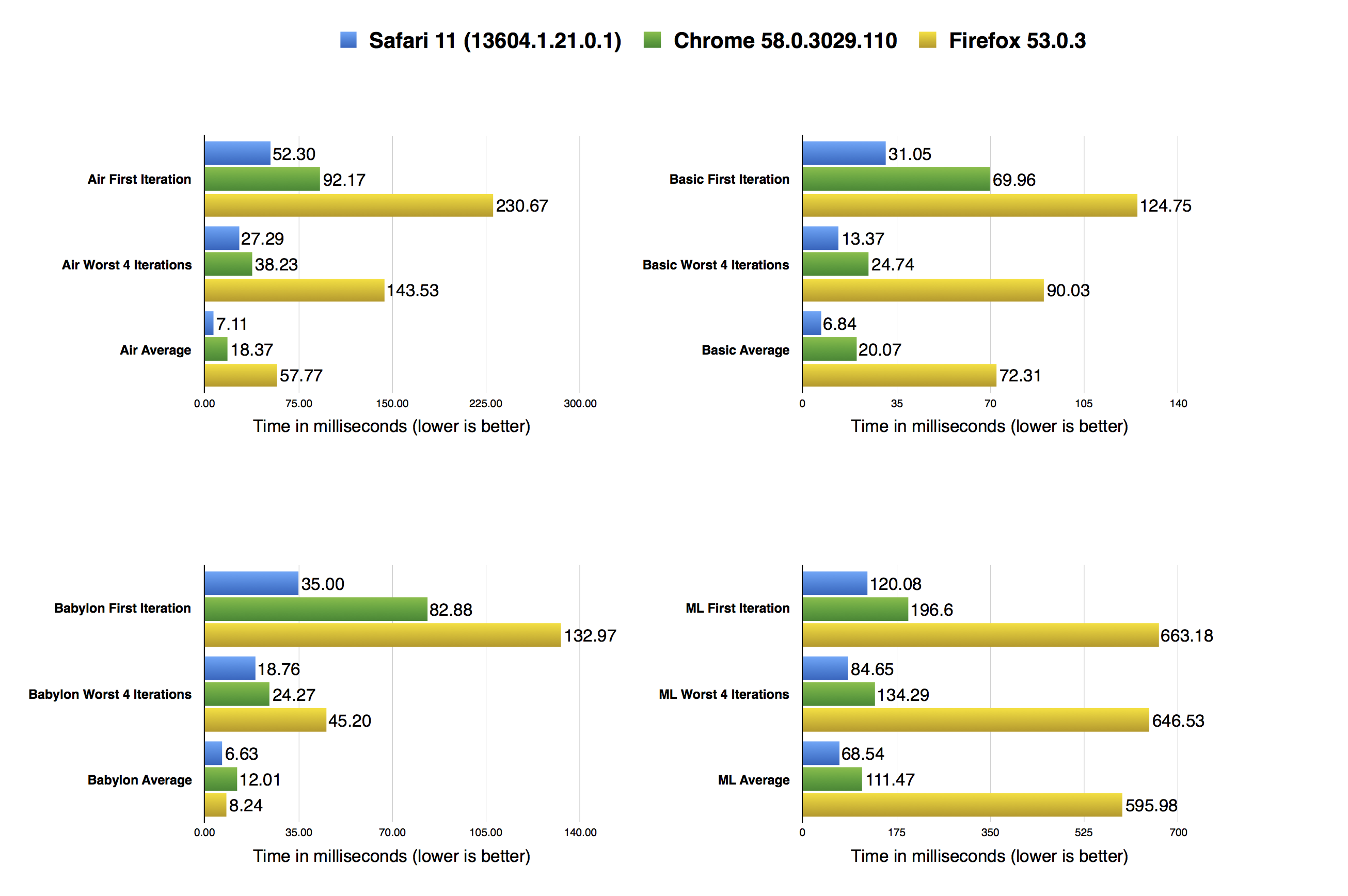
The graph above shows detailed results for all four benchmarks and their three scores. It shows that JavaScriptCore is the fastest engine at running ARES-6 not only in aggregate score, but also in all three scores for each individual subtest.
Conclusion
ES6 is a major improvement to the JavaScript language, and we had fun giving it a test drive when creating ARES-6. Writing Air and Basic, and importing Babylon and ML, gave us a better grasp of how ES6 features are likely to be used. Adding new benchmarks to our repertoire always teaches us new lessons. Long term, this only works to our benefit if we keep adding new benchmarks and don’t over optimize for the same set of stale benchmarks. Going forward, we plan to add more subtests to ARES-6. We think adding more tests will keep us honest in not over-tuning for specific ES6 code patterns. If you have exciting ES6 (or ES7 or beyond) code that you think is worth including in ARES-6, we’d love to hear about it. You can get in touch either by filing a bug or contacting Filip, Saam, or Yusuke, on Twitter.