A Tour of Inline Caching with Delete
If you search for any JavaScript performance advice, a very popular recommendation is to avoid the delete operator. Today, this seems to be good advice, but why should it be vastly more expensive to delete a property than to add it?
The goal of my internship at Apple this winter was to improve the performance of the delete operator in JavaScriptCore. This has given me the opportunity to learn about how the various pieces of JavaScriptCore’s inline caching optimizations work, and we will take a quick tour of these optimizations today.
First, we will look at how expensive deletion really is in the major engines, and discuss why we might want to optimize it. Then, we will learn what inline caching is by implementing it for property deletion. Finally, we will look at the performance difference these optimizations make on benchmarks and microbenchmarks.
How expensive is Deletion?
First of all, why should we even bother optimizing deletion? Deletion should be fairly rare, and many JavaScript developers already know not to use it when possible. At the same time, we generally try to avoid having large hidden performance cliffs. To demonstrate how a simple delete statement can have a surprising effect on performance, I wrote a small benchmark that renders a scene progressively, and measures the time it takes to render each frame. This benchmark is not designed to precisely measure performance, but rather to make it easy to see large performance differences.
You can run the program yourself by pressing the run button below, which will calculate a new color value for every pixel in the image. It will then display how long it took to render, in milliseconds.
Next, we can try executing a single delete statement to a hot part of the code. You can do this by checking the “Use Delete” checkbox above, and clicking run again. This is what the code looks like:
class Point {
constructor(x, y, z) {
this.x = x
this.y = y
this.z = z
this.a = 0
if (useDelete)
delete this.a
}
}
The following results were measured on my personal computer running Fedora 30, comparing tip of tree WebKit (r259643) with all of the delete optimizations both enabled and disabled. I also used Firefox 74 and Chromium 77 from the Fedora repositories.
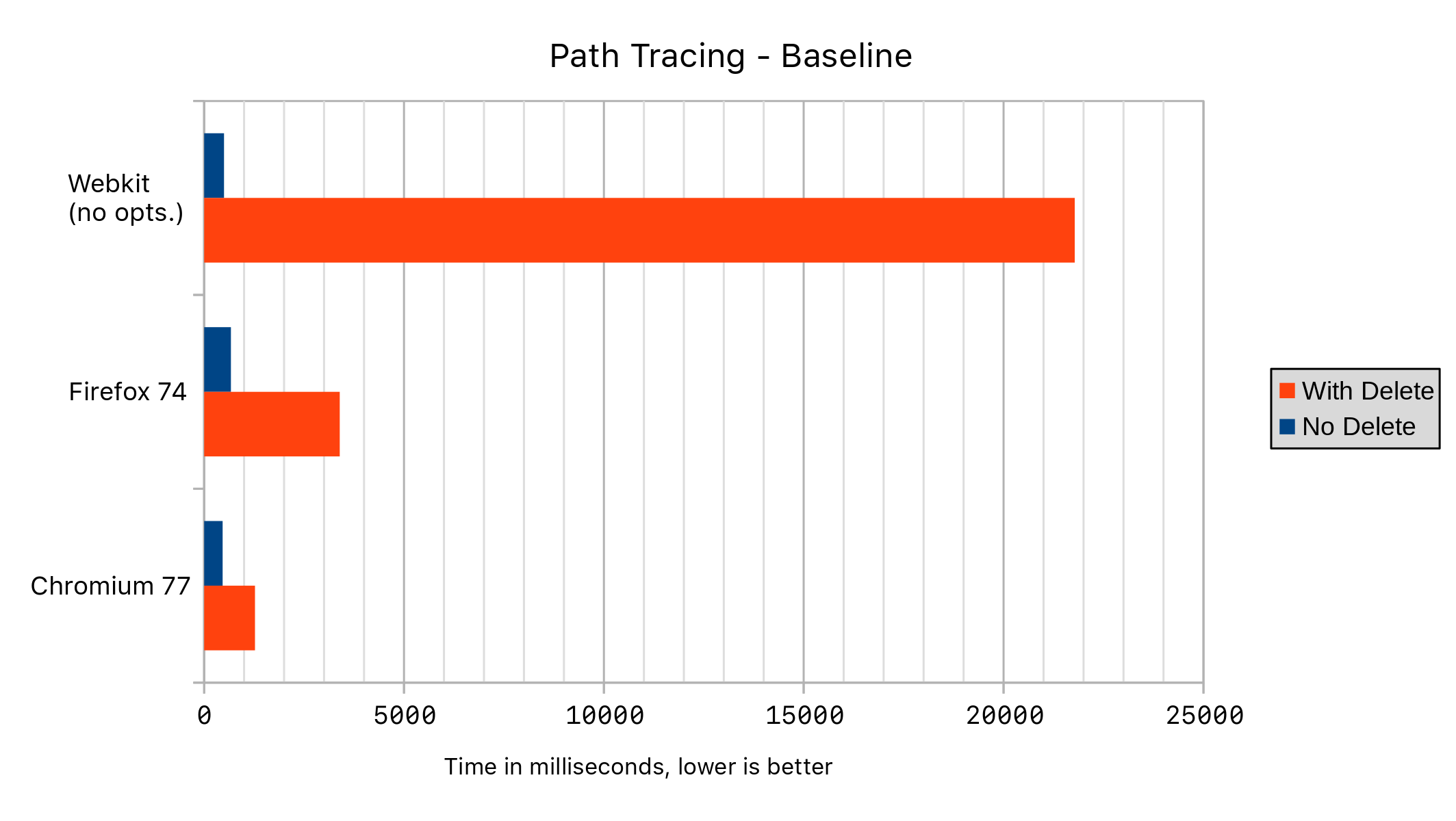
Here, we can see that the addition of a delete statement to a hot section of code can send the performance off a cliff! The primary reason for this is that deletion in JavaScriptCore used to disable all of the inline caching optimizations for an object, including when putting and getting properties of the object. Let’s see why.
Structures and Transitions
JavaScript code can be extremely dynamic, making it tricky to optimize. While many other languages have fixed-size structs or classes to help the compiler make optimizations, objects in JavaScript behave like dictionaries that allow associating arbitrary values and keys. In addition, objects frequently change their shape over time. For performance, JavaScriptCore uses multiple internal representations for objects, choosing between them at runtime based on how a program uses them. The default representation of objects use something called a Structure to hold the general shape of an object, allowing many instances that have the same shape to share a structure. If two objects have the same structure ID, we can quickly tell that they have the same shape.
class A {
constructor() {
this.x = 5
this.y = 10
}
}
let a = new A() // Structure: { x, y }
let b = new A() // same as a
Structures store the names, attributes (such as read-only), and offsets of all of the properties owned by the object, and often the object’s prototype too. While the structure stores the shape, the object maintains its property storage, and the offset gives a location inside this storage.
At a high level, adding a property to an object using this representation goes as follows:
1) Construct a new structure with the property added.
2) Place the value into the property storage.
3) Change the object’s structure ID to point to the new structure.
One important optimization is to cache these structure changes in something called a structure transition table. This is the reason why in the example above, both objects share the same structure ID rather than having separate but equivalent structure objects. Instead of creating a new structure for b, we can simply transition to the structure we already created for a.
This representation improves performance for the case when you have a small number of object shapes that change predictably, but it is not always the best representation. For example, if there are many properties that are unlikely to be shared with other objects, then it is faster to create a new structure for every instance of this object. Since we know that there is a 1:1 relationship between this object and its structure, we no longer have to update the structure ID when making changes to the shape of the object. This also means that we can no longer cache most property accesses, since these optimizations rely on checking the structure ID.
In previous versions of JavaScriptCore, this is the representation that was chosen for any object that had a deleted property. This is why we see such a large performance difference when a delete is performed on a hot object.
The first optimization of my internship was to instead cache deletion transitions, allowing these objects to continue to be cached.
class A {
constructor() {
this.x = 5
this.y = 10
delete this.y
}
}
let a = new A() // Structure: { x } from { x, y }
let b = new A() // same as a
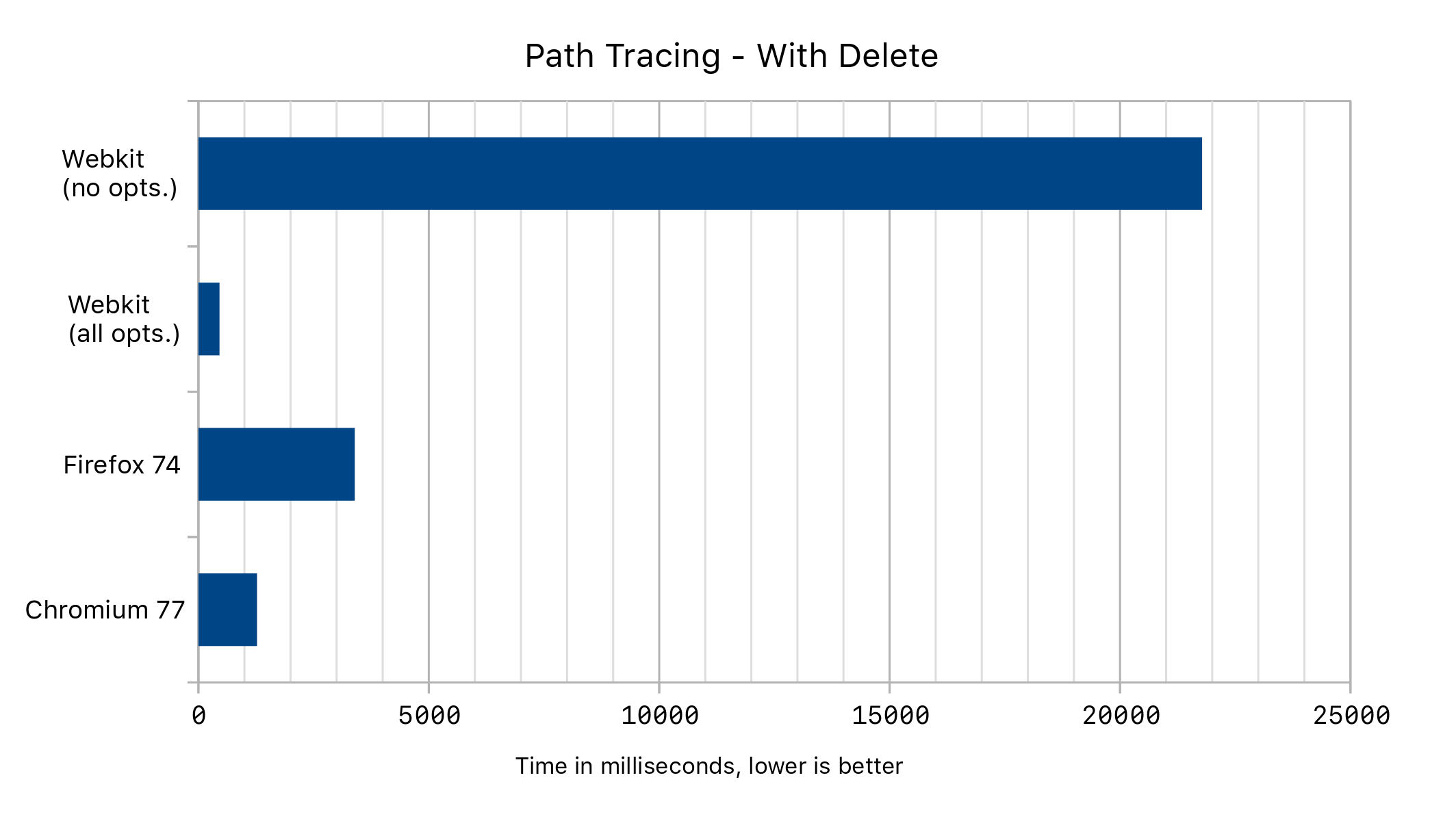
Before this change, both a and b had distinct structures. Now they are the same. This not only removes our performance cliff, but will enable further optimizations to the deletion statement itself.
In the path tracing example above, we get the following performance results:
Inline Caching
Now that we can cache deletion transitions, we can further optimize the act of property deletion itself. Getting and putting properties both use something called an inline cache to do this, and now deletion does too. The way this works is by emitting a generic version of these operations that modifies itself over time to handle frequent cases faster.
I implemented this optimization in all three of our JIT compilers for delete, and our interpreter also supports inline caching. To learn more about how JavaScriptCore uses multiple compilers to trade-off latency and throughput, see this blog post. The summary is that code is first executed by the interpreter. Once it is sufficiently hot, it gets compiled into increasingly optimized pieces of machine code by our compilers.
An inline cache uses structures to keep track of the object shapes it has seen. We will see how inline caching now works for delete, which will give us some insight into how it works for getting and putting properties too.
When we see a delete property statement, we will first emit something called a patchable jump. This is a jump instruction that can be changed later on. At first, it will simply jump to some code that calls the slow path for property deletion. This slow path will store a record of this call, however, and after we have performed a few accesses, we will attempt to emit our first inline cache. Let’s walk through an example:
function test() {
for (let i = 0; i < 50; ++i) {
let o = { }
if (i < 10)
o.a = 1
else if (i < 20)
o.b = 1
else
o.c = 1
delete o.a
}
}
for (let i = 0; i < 100; ++i)
test()
First, we run test a few times causing it to tier up to the baseline compiler. Inside test(), we see that the code deletes properties from objects with three different structures, while giving enough time for us to emit a new inline cache for each. Let’s see what the baseline code looks like:
jmp [slow path] ; This jump is patchable
continuation:
[package up boolean result]
; falls through to rest of program
...
slow path:
[call into C++ slow path]
jmp [next bytecode]
This code performs a few checks, then jumps either to the slow path call or the patchable jump target. The slow path call is placed outside the main portion of the generated code to improve cache locality. Right now, we see that the patchable jump target also points to the slow path, but that will change.
At this point in time, deletion is a jump to the slow path plus a call into C++, which is quite expensive.
Every time the slow path call is made, it collects and saves information about its arguments. In this example, the first case that it decided to cache is the delete miss for the structure with shape { c }. It generates the following code, and repatches the patchable jump target to go here instead:
0x7f3fa96ff6e0: cmp [structure ID for { c }], (%rsi)
0x7f3fa96ff6e6: jnz [slow path]
0x7f3fa96ff6ec: mov $0x1, %eax ; return value true
0x7f3fa96ff6f1: jmp [continuation]
0x7f3fa96ff6f6: jmp [slow path]
We see that if the structure ID matches, we simply return true and jump back to the continuation which is responsible for packaging up the boolean result and continuing execution. We save ourselves an expensive call into C++, running just a few instructions in its place.
Next, we see the following inline cache get generated as the engine decides to cache the next case:
0x7f3fa96ff740: mov (%rsi), %edx
0x7f3fa96ff742: cmp [structure ID for { c }], %edx
0x7f3fa96ff748: jnz [case 2]
0x7f3fa96ff74e: mov $0x1, %eax
0x7f3fa96ff753: jmp [continuation]
case 2:
0x7f3fa96ff758: cmp [structure ID for { a }], %edx
0x7f3fa96ff75e: jnz [slow path]
0x7f3fa96ff764: xor %rax, %rax; Zero out %rax
0x7f3fa96ff767: mov %rax, 0x10(%rsi); Store to the property storage
0x7f3fa96ff76b: mov [structure ID for { } from { a }], (%rsi)
0x7f3fa96ff771: mov $0x1, %eax
0x7f3fa96ff776: jmp [continuation]
Here, we see what happens if the property exists. In this case, we zero the property storage, change the structure ID, and return true (0x1), to the continuation for our result to be packaged up.
Finally, we see the complete inline cache:
0x7f3fa96ff780: mov (%rsi), %edx
0x7f3fa96ff782: cmp [structure ID for { c }], %edx
0x7f3fa96ff788: jnz [case 2]
0x7f3fa96ff78e: mov $0x1, %eax
0x7f3fa96ff793: jmp [continuation]
case 2:
0x7f3fa96ff798: cmp [structure ID for { a }], %edx
0x7f3fa96ff79e: jnz [case 3]
0x7f3fa96ff7a4: xor %rax, %rax
0x7f3fa96ff7a7: mov %rax, 0x10(%rsi)
0x7f3fa96ff7ab: mov $0x37d4, (%rsi)
0x7f3fa96ff7b1: mov $0x1, %eax
0x7f3fa96ff7b6: jmp [continuation]
case 3:
0x7f3fa96ff7bb: cmp [structure ID for { b }], %edx
0x7f3fa96ff7c1: jnz [slow path]
0x7f3fa96ff7c7: mov $0x1, %eax
0x7f3fa96ff7cc: jmp [continuation]
When we run the code above in different browsers, we get the following performance numbers with and without delete optimizations:
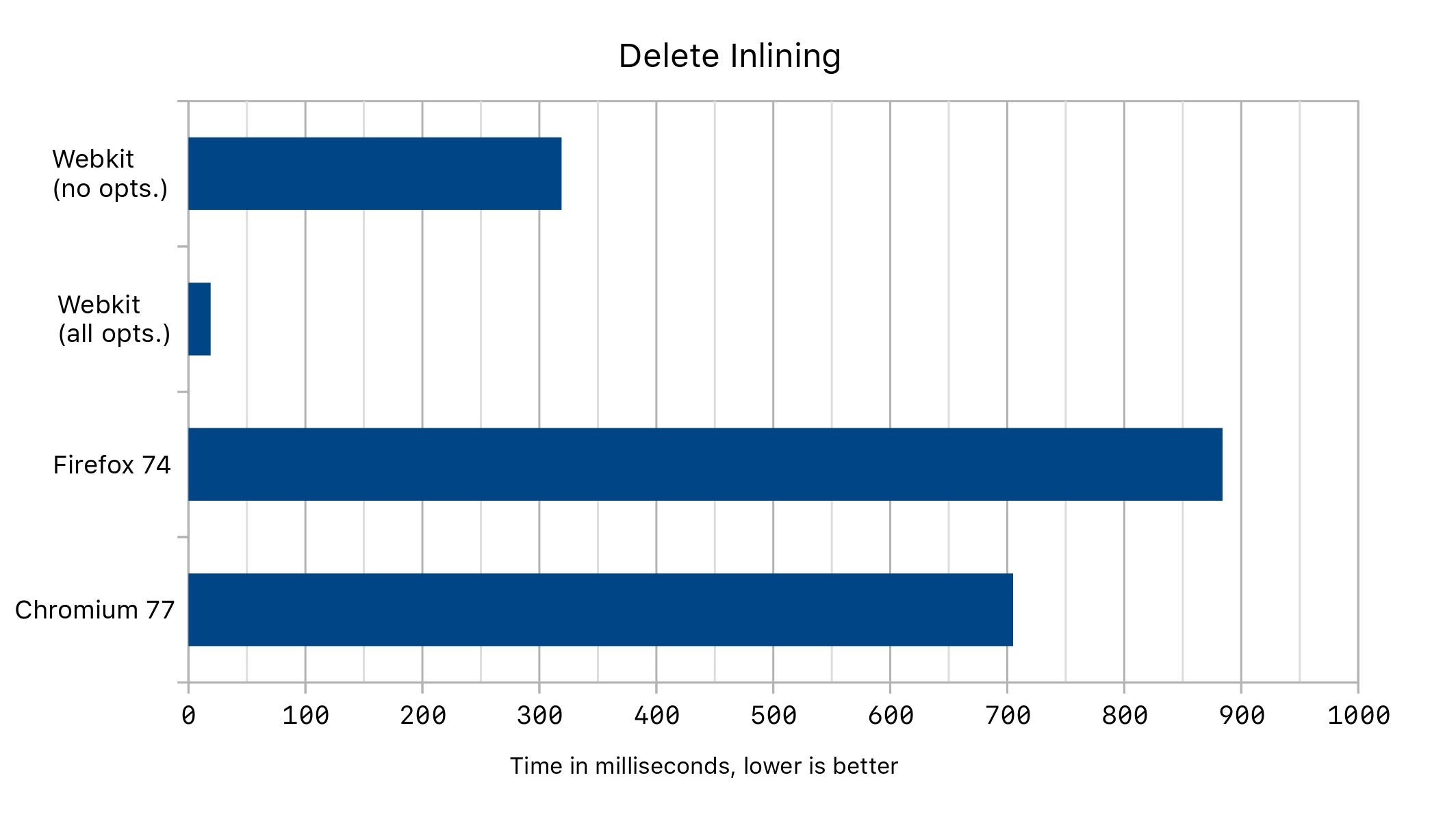
Inlining Delete
Now that we have seen how an inline cache is generated, we would like to see how we can feed back this profiling information into the compiler. We will see how our first optimizing compiler, the DFG, can attempt to inline delete statements like it already does for puts and gets. This will then allow all of the other optimizations we have to see inside the delete statement, rather than seeing a black box.
We will demonstrate this by looking at just one of these optimizations, our object allocation sinking and elimination phase. This phase attempts to prevent allocations of objects when they do not escape their scope, but it previously saw property deletion as an escape. Consider the following code:
function noEscape(i) {
let foo = { i }
delete foo.x
return foo.i
}
for (let i = 0; i < 1000000; ++i)
noEscape(5)
As the delete is run, it will first get an inline cache. As the code continues to tier up, the DFG tier will eventually look at the cases covered by the inline cache and see only one structure. It will decide to try inlining the delete.
It first speculates that the structure ID of the target object is for the structure with shape { i }. That is, we check that the structure of the object matches, and if it does not, we exit to lower-tier code. This means that our engine can assume that the structures match for any subsequent code. If this assumption turns out to be false, we will eventually recompile the code again without it.
D@25: NewObject()
D@30: CheckStructure(D@25, Structure for { })
D@31: PutByOffset(D@25, D@25, D@36, id0{i})
D@32: PutStructure(D@25, Structure for { i })
D@36: CheckStructure(D@25, Structure for { i })
D@37: JSConstant(True)
D@42: CheckStructure(D@25. Structure for { i })
D@43: GetByOffset(D@25, 0)
D@34: Return(D@43)
We see here that we make a new object, and then see inlined versions of put, delete and get. Finally, we return.
If the delete statement were compiled into a DeleteByID node, later optimizations could not do much to optimize this code. They don’t understand what effects the delete has on the heap or the rest of the program. We see that once inlined however, the delete statement actually becomes very simple:
D@36: CheckStructure(D@25, Structure for { i })
D@37: JSConstant(True)
That is, the delete statement becomes simply a check and a constant! Next, while it often isn’t possible to prove every check is redundant, in this example our compiler will be able to prove that is can safely remove them all. Finally, our object allocation elimination phase can look at this code and remove the object allocation. The final code for noEscape() looks like this:
D@36: GetStack(arg1)
D@25: PhantomNewObject()
D@34: Return(D@36)
PhantomNewObject does not cause any code to be emitted, making our final code trivial! We get the following performance results:
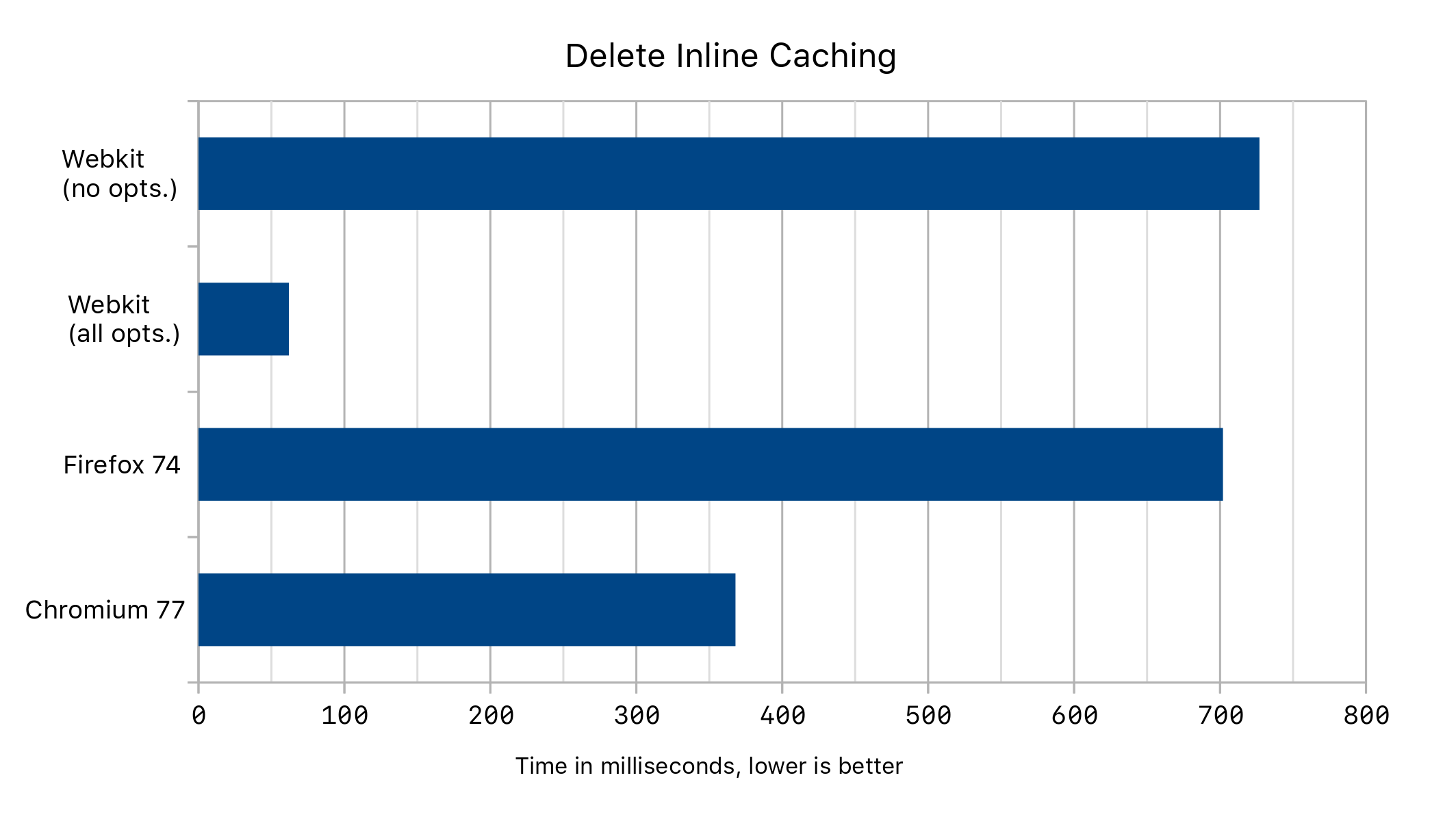
Results
The caching of delete transitions caused a 1% improvement overall on the speedometer benchmark. The primary reason for this is that the EmberJS Debug subtest uses the delete statement frequently, and delete transition caching progresses this benchmark by 6%. This subtest was included in the benchmark because it was discovered that many websites do not ship the release version of EmberJS. The other optimizations we discussed were all performance-neutral on the macro-benchmarks we track.
In conclusion, we have seen how inline caching works first-hand, and even progressed a few benchmarks in the process! The order that we learned about these optimizations (and indeed the order that I learned about them this term) follows closely the order that they were discovered too. If you would like to learn more, check out these papers on implementations of inline caching in smalltalk and self, two languages that inspired the design of JavaScript. We can see the evolution from monomorphic inline caches in smalltalk to polymorphic inline caches with inlining support in self, just like we saw on our tour today. Implementing inline caching for delete was an extremely educational experience for me, and I hope you enjoyed reading about it.
While deletion will still be rare, it still feels great to make JSC even more robust. You can get in touch by filing a bug or by joining the WebKit slack workspace. You can also consider downloading the code and hacking on it yourself!